

我今天的主题是“AI大潮下如何创新”,创新是非常难谈的话题,尤其在创新的路上摸爬滚打,失败往往多于成功。
2023年是人类科技史上特别重要的一年,我特别喜欢的科普作家卓克,把2023年定义为人类科技奇迹年。科技奇迹是指:一个新事物的出现彻底改变人类社会。
奇迹年之一:1666年,牛顿发布万有引力定理和微积分,使得现代文明、工业大厦由此展开。
奇迹年之二:1905年,爱因斯坦发布了四篇论文,奠定了今天所有关于计算机科学、量子力学的基础。
奇迹年之三:2023年,ChatGPT的横空出世,使得人类对科学的探索达到新的高度。

在这样的科技大潮之下,带来整个人类社会底层的重构。这意味着所有人的工作方式、思考方式都要发生变化。因为自身不变化就会跟不上时代的变化,更不要谈如何创新。但如何抓住是非常复杂的话题,所以我想从个人经历的科技大潮小故事开始。
大概20年前,我来到了北京,当时存折只有400元,那个时候也很卷,住过地下室,挤过300路(北京三环最著名的挤不上去的公交线)。
但一个非常有幸的机会,在2002年进入互联网,每天起早贪黑,用我自己的感受来形容那段工作时光,就是下过班没有看见过太阳。
20多岁的时候,我说30岁之前有三个愿望要实现,一是存款有一百万;二是可以到国外看一看,第三个愿望记不住了,因为都没有实现。那时候看到互联网的蓬勃发展,看过顶尖的弄潮儿,但是发现跟不上。
现在回头看,每个大变革的时代,作为普通人的有心无力,真的没有办法让自己抓住这次浪潮。
后来过了30岁之后,有一次旅行到了一个地方——斯坦福,站在斯坦福的大草坪前我震惊了,不是草坪有多大,而是大草坪上竟然有人跑步。那是一个工作日,他们怎么会有时间跑步?之后又站到101高速路的天桥上,看到往海边的方向堵车,原因是大家拖着小船、游艇度假去了。
我的震惊是为什么在北京,大家每天工作加班累成狗,但他们却这么休闲?那时候给我的震撼相当之大,我在想,原来我这么勤奋并不是可以做出一些事情的充分条件。
遍访这些美国初创公司后,我发现,如果只靠勤奋,那就是今天社会可能的状态,同质化的勤奋就是卷。

不同的道路才可能胜出,因为你勤奋,对手会比你更勤奋,你不要利润,你的对手可以亏着卖,尤其是大公司,它可以不计成本的把你按下去。
一、创新的不二法门:找到不同的路
在帆船理论当中,领先的帆船只要跟着后面的帆船变帆,后者永远不可能超越前者,因为大家的风是一样的。即便是大潮当中,不去思索不一样的路,你也不可能实现超越。
后来仔细想什么叫创新?创新就是在不同的路上找到出路,那样才能更小投入、更大产出。
当时看到苹果一九八几年宣传片的时候,我说这个文化很牛,认真思考这件事发现,Think Different(另类思考)不是特立独行的文化,而是创新的底层思维模式。
翻开美国的历史可以看到,金门大桥是一九三几年建成的,帝国大厦是一九三几年建成的。60年代,他们的高速公路已经铺到村村通。相信他们也经历过很卷的时代,到八几年美国经济滞胀,甚至要被日本超越,但是美国找到一个新的互联网道路,实现新一轮的技术创新。
在今天的时代下,经济总量到达一定规模,每一个创业者应该找到不同的道路,而不是比你做得更好的道路。
最近,OpenAI的创始人推荐了一本书——《为什么伟大不能被计划?》,他说OpenAI的出现不是必然,甚至是偶然,因为正是在大家看不到的道路上有人在尝试,发现了一条路,于是做了出来。
只有Think Different才能实现创新,才能跨越式发展,但是新的道路往往不在大多数人的认知地图中,正因如此,Think Different从最开始不被大多数人看好。
我正是想清楚了这一个底层规律,所以在2012年,国内移动互联网创新最卷的时候,让猎豹移动All in出海。
大家都知道的TikTok,当年我们是最早的天使投资人。当时没有人相信上海十个人的团队做美国的音乐短视频App可以火起来,但我相信Think Different总是有机会,这就是一条不同的路。
在2016年,互联网发展到各种新兴事物层出不穷,例如百团大战、小黄车大战,那时候在想,如果再开启一条曲线,我想做不同的事情,所以那时候我们就喊出All in AI。
当时看到AI的时候,就觉得这是一次范式的变化,改变过去编程以过程控制为核心,而实现某种意义上的端到端,给它足够的数据让计算机自己理解。
由于那个时候起步较早,我们的AI也有一些技术优势——在语音识别领域做到了行业领先。例如小爱同学、小美AI音箱的语音识别是我们提供的,喜马拉雅智能音箱的全套技术方案也是我们提供的。
今天看到一个朋友说猎豹做了七年AI是吹牛,大模型才出来一年,但我想说,AI出来已经不止一年。
这是我们画的AI1.0的技术树,从最早DNN、CNN,到后来的Attention、Transformer,所有的公司开始认识到AI的巨大改变。于是,大家一起在这棵树上往上成长。
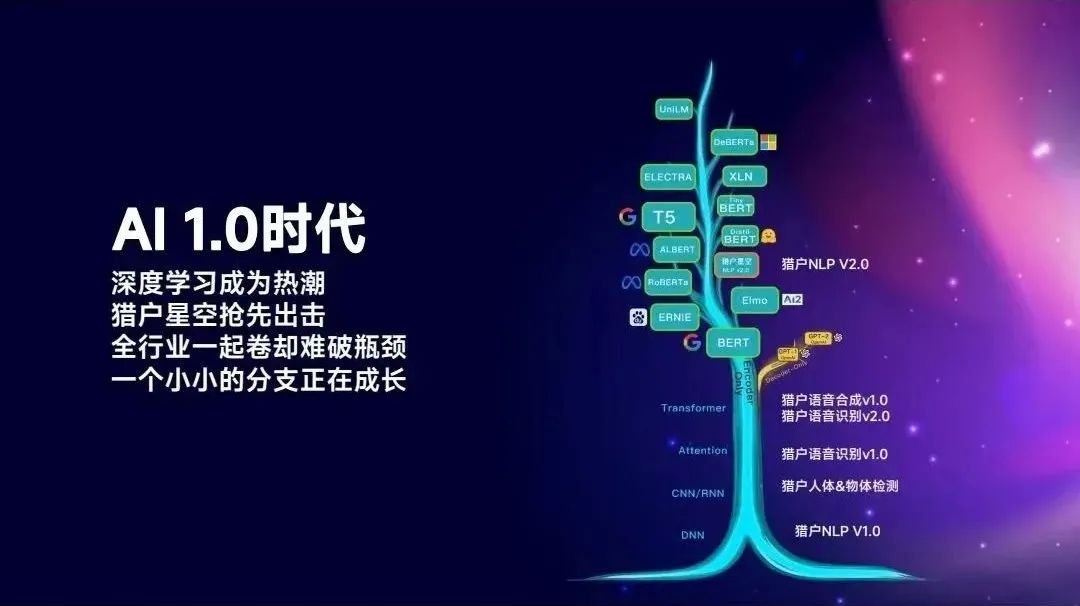
其实在2016年、2017年,大家对AI的判断是:出来就可以改变世界。我们做好了视觉识别,就可以做好语音识别,语音识别做好了,就可以理解语言,理解语言就可以自动驾驶。但事实上,在2018年、2019年,这棵树长不上去了。
这时候出现一个分支,也就是GPT1、GPT2。大家可能不知道的是,在GPT2发布的时候,整个OpenAI就是硅谷的“笑话”,通过预测下一个词怎么就产生智能,这件事不靠谱,如果靠谱谷歌为什么不做?
直到2022年11月30日ChatGPT横空出世,当时使用后非常激动。因为语言是计算机理解上最难的事情。
人类是先有智能还是先有语言,这件事在学术界没有定论,但语言构建了我们对整个世界的认知,对逻辑的理解、推理,从而产生智能。所以当ChatGPT可以通过大量语料学习,完成对语音的理解时,那么离通用人工智能就不远了。
李开复把ChatGPT的出现定义为AI2.0时代,这不是在原来的路线上长出来的,而是在分支中爆发出来的。
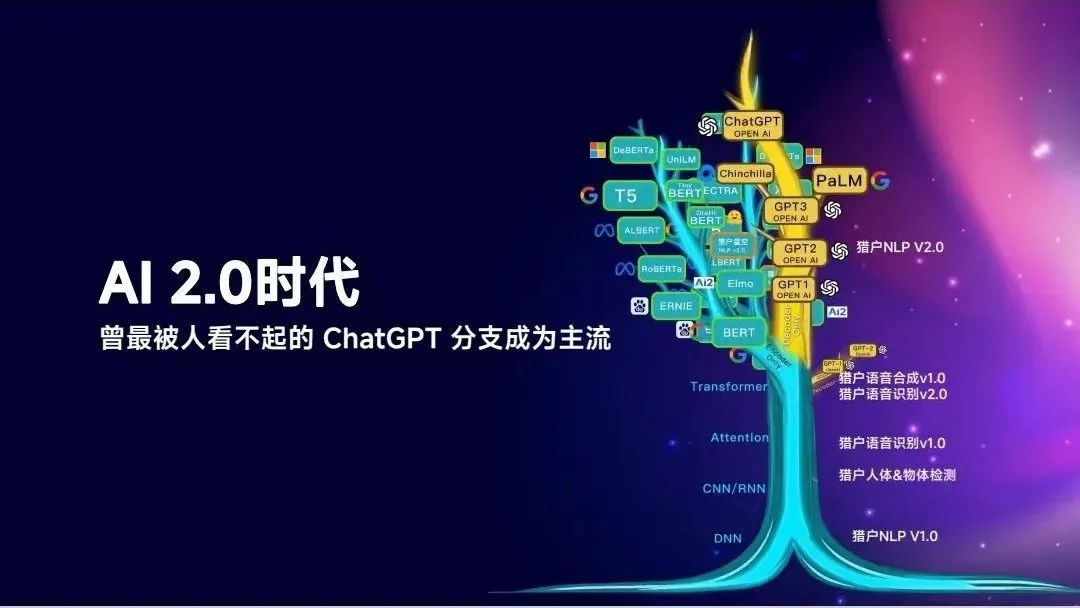
回过头来看,ChatGPT就是Think Different。OpenAI最早做了四个项目:OpenAI Universe、OpenAI Five、魔方机器人、ChatGPT。
ChatGPT是他们公司里面最不看好的,一个小聊天没有什么好做的,前面三个项目得到的资源都比ChatGPT多。

OpenAI的出现,改变了机器学习里非常重要的技术路线——以前我们认为让计算机学会语言,就像我们学英语一样,需要学习语法、字词,这是比较符合我们的认知。但只有OpenAI相信,由于Transformer的出现,使得计算机可以处理大量的数据,给它足够多的文本,可以自然产生对语音的理解。
一旦对语言理解,AI就具备了推理和认知逻辑能力,产生了智能化。

很多人问我为什么OpenAI做出来了,是不是他们的科学家特别牛,这当然很重要,但它不是技术积累的成功,而是信仰的成功。
他们的原理上有自己的一套理论,首席科学家说为什么预测下一个词就可以变成智能,就好像读完一本侦探小说,最后要填杀手是谁,如果填对就代表对前面的所有都理解了,所以每一个下一次预测都是智能的涌现。
OpenAI出现后大家很困惑,怎么这么多人做大模型,这个技术不是很高深吗?我想说,如果作为人工智能的从业者而言,它并不高深,而是一棵树上的分支,无论是神经网络还是Transformer,都是我们所积累的技术。所以,不是技术积累的胜利,而是在这条路上全力以赴Think Different。
花了这么大的篇幅讲我的故事到OpenAI的故事,我想说的是——回顾当时的互联网创业大潮,再看这一次AI科技大潮,想在这个大潮中找到创新的法门,一定要有Think Different的思维逻辑,一定要找一条不是大家都在走的路,如果所有人一拥而上,相信这条路也很难走通。

今天,几乎所有的伟大创新公司都是Think Different的成果,无论是苹果、特斯拉还是OpenAI,今天提这些公司都觉得特别厉害,但当初都是被质疑,甚至是被嘲笑。
苹果手机刚出来的时候,真的被笑话,发短信太慢、信号又不好。特斯拉Model3出现之前,所有的汽车工业没有一个觉得埃隆马斯克可以把特斯拉做成。
当然,Think Different也有很多失败之处,这时候我们就要不停地思考、不停地复盘总结,不断寻找那条路,一旦找到那条路,创新就属于你。
二、AI大模型创新,
依然可以有新路径
1.ChatGPT是一次生产力革命
生产力革命的定义是很少见,人类历史上可能只有蒸汽机的出现叫做一次生产力革命,在蒸汽机出现之前,所有的搬砖能力只能靠人或者牛和马,愚公移山只能靠多生孩子,烧火只能用来加热食物。
蒸汽机出现后,能量的转化范式发生了变化,人类生产力大幅度提高,工业文明开始。
而ChatGPT由于具备语言理解,产生了人类独有的逻辑力和推理力。
这使得今后电脑有可能实现对智能的转换,以前我们要做一个智能系统要用很多人、很多实施,成本非常高,但费用不是边际递减。而ChatGPT出现后,有可能放一台电脑就可以像人一样工作。
这一次变革之大,不仅是企业界在关注,各国领导人都在关注。这一次的生产力变革,使得国家之间的智能竞争不再是人口和教育数字,而是人口教育数字+算力。而每一家企业可能未来真正的智能水平也不只靠有经验的员工,而是靠有经验的人和很厉害的算力,这件事在硅谷已经出现了。
今天这个时代,已经有些企业开始崛起,如果业务都用大模型重做一遍,十倍增长一定可以达到。

比如,微软。2023年,微软从老态龙钟的科技巨头焕发了新的活力。微软以前的Slogan是让每一个家庭都有一台电脑,现在就可以给每一个人提供助理,它的业务规模就会有很大想象空间。
还有Midjourney,现在年收入超过2亿美金,如果只看它是一个玩图的网站,那想象不到它的商业价值,但如果把它跟类似猪八戒网的网站对齐,它就是提供设计外包,以前要找无数的设计师满足对的需求,现在只要在网站点几下,就可以获得你要的,所以它的生产力大幅度提升。
还有中国的公司HeyGen,它就做了一个应用,把现在的演讲变成英语、日语,把口形对准,现在年收入1800万美金。
Pika也是最近硅谷很热的一家公司,以前修改视频要找专业团队,但是Pika说我的模型可以直接做。
2.AI,是能力放大器
以上这些事情大家都已经相信,但是要怎样面对这一次AI大潮,听到更多的是不知道怎么做,总结两句话:
第一,这一波技术来得太猛,很多人问我,以后是不是不懂技术、不会编程就要被淘汰,以后都是理工男的天下,我们完全不懂AI到底是什么。
第二,变得太快了,刚学一些又有新的技术出现。
我认为,这一波AI的到来不是淘汰不懂技术的人,而是给不懂技术的人一个非常强大的支撑。

以后谁懂业务,谁懂离计算机远的行业的规律,那谁就有可能被AI放大其能力,可能是十倍、百倍的放大。因为以前技术只属于程序员,但今天不用了,AI使得技术的鸿沟被拉平,技术被平权化。
但是我想说万变不离其宗:所有的技术浪潮无论听起来有多神奇,都应该躬身入局,以终为始,找一条适合自己的路。
3.千亿大模型VS应用模型
2023年3月份,国内千亿大模型创业如火如荼,所有人都要做中国的OpenAI。
我的团队也找到我,说ChatGPT我们懂,OpenAI很早就用在NLP上,跟我讲做这个东西要准备好钱,赶快买A100。我当时也想冲动,但我在这个行业做了七年,清楚第一波完全是不计成本的投入,所以我也抑制住了激动的心情,说等我想想。
2023年4月份,我跟出门问问的李志飞聊,他说不要做,因为再过半年,中国会有很多千亿大模型,到时候千亿大模型过剩没有人用,但如果不训好像赶不上这波大潮,只有做才是唯一路径。
我想起当时第一波做AI1.0的时候,招了很多博士,做的很多技术都可以发论文。但我要坦诚的说,第一代机器人做得并不好,后来决定机器人需要什么就把哪个AI技术打磨好,而不是先搞一堆技术放在那里。
这时,我想起一句话:再高深的技术没有商业落地,都只是技术狂欢;脱离市场的技术投入,都是资源浪费。

这个观念今天讲出来需要勇气,因为天天大家都在讲硬科技等等,如果坦诚来看,在AI1.0时代,很多AI公司并没有真正实现闭环,或者实现的闭环并不够好,烧了很多钱并没有独到的东西,这是事实。
我看过一个乔布斯的录像——技术到底为何而存在?他说,不是为了工程师的技术本身而存在,而是为了应用而生。

有一个数据显示,在苹果推出手机的时候,研发费用上投入的资金远低于诺基亚。正是因为这种以终为始的创新文化,使得它可以做到高效创新,真正把一件符合用户需求的技术打磨到极致。
今天再回头看苹果,iPhone发布的时候,没有一个部件是自己生产的,没有一个App是自己做的,它完成了应用整合,之后创造了足够用户价值后,反向再做各项技术。今天,苹果芯片出来的时候秒杀所有芯片,M1、M2给芯片行业带来的震撼是巨大的。

所以我总结了两套模式:一种是训练千亿级模型,做垂直模型,再寻找应用场景;另一种是挖掘应用场景,做垂直模型,再打造适合的模型。
我们当时选择了第二条路,我对团队说,这次科技浪潮不是一年的事,甚至不是十年的事,有的是时间,我们先从应用出发,挖掘应用场景,寻找垂直模型,真正准备好了我们再开始训练。我相信这么一个大赛道下,有的是机会。
4.全员参与AI变革
那个时候,我自己带一个笔记本跟ChatGPT对话,让它教我写程序,教我各种东西,我发现有用以后我跟全员说,所有的部门都要参与到AI变革中。
最后通过内部创新的方式,涌现出一些特别惊人的例子。这个例子就是我们的CFO助理,他没学过编程,用了ChatGPT后,写了关于他工作相关的工具,比如Word转PDF,加水印。
而且不仅他用,我们法务、财务同事都在用,说这个比专业团队做的还好用,震惊了所有的程序员。
当时我跟程序员聊天的时候说你未来怎么规划,他说我都不敢想,因为佩琪(助理)都做出那么多程序了,我的价值何在。
所以我再回答开始那个问题,OpenAI是一个技术浪潮,但是不是让更懂技术的更牛,而是让不懂技术的人能够跨越技术的鸿沟。
通过近一年的时间,我们发现大模型在企业增效中非常明显,但是只靠员工自我驱动难以落实。所以,要一把手亲自抓,而且要对流程进行AI重构。
所以,我们公司成立了AI生产力部门,把过去散落在各地的中台部门全部统一到这个部门里,而且直接向我汇报。
5.不是千亿模型做不起,而是百亿更有性价比
总结起来,AI前景很大,但现在真的是早期,大模型落地需要强应用。今天,你说一个API就能够让企业增长20%的效率,这是不可能的。
很多媒体朋友知道,我吵架经常会上微博热搜。有人说AI大模型对创业者不友好,99%的能力都是被大模型覆盖的,创业公司有什么价值?我就怼了一下,很多人以为我是一时兴起,但是事实上不是的,因为在这之前我们实践了太多——让大模型做好一个基本问答,都要做非常大的努力。
通过躬身入局,我想起来古人两句诗“纸上得来终觉浅,绝知此事要躬行”,你只看朋友圈就觉得AI要吞噬人类,未来全人类只需要一家公司就是OpenAI,但是你真正动手做,发现太多的细节是可以去做的。

简单来说,如果一个底层技术很牛,就能做出一切,芯片公司将统领所有行业,但并不是这样的。底层技术有底层技术的价值,应用有应用的价值。
2023年5月,有客户说能不能私有化部署,因为我们这个客户是政务客户,涉及到社保公积金的老百姓问答,他说这个东西不能放在公网上。
当时一个千亿参数大模型一年私有化授权费用是几千万,到今天应该还是。客户说,我们就想做一个客服,这个AI大模型那么牛,我一年投个几千万划不来,你再高深的技术最后还得算账,有没有更便宜又不损失性能的方案。
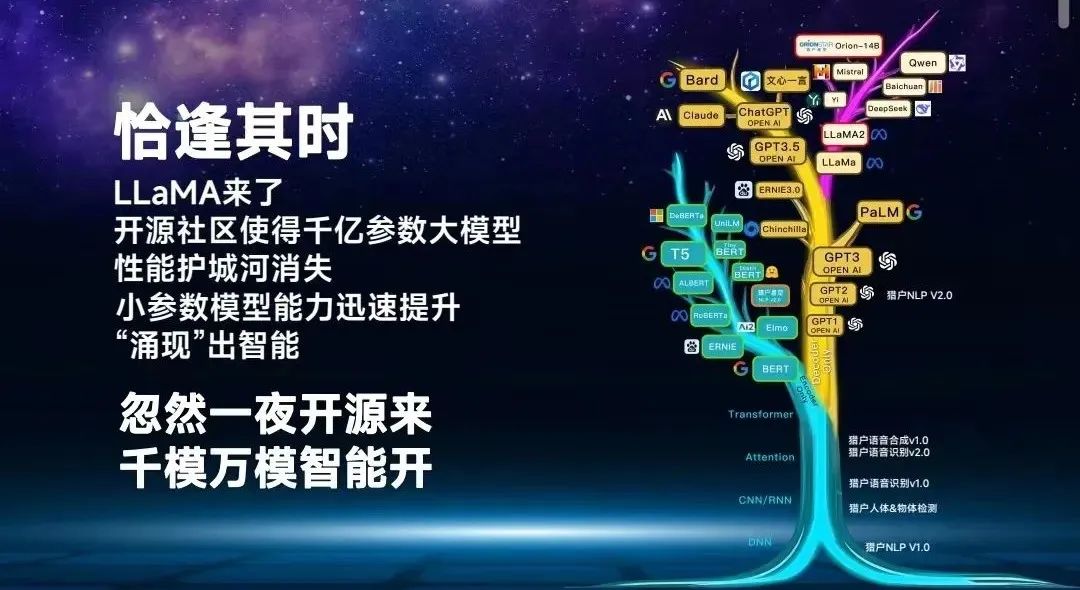
五六月份的时候,行业又发生了变化,LLaMA来了。LLaMA滋养了很多大模型公司,使得大模型的算法壁垒快速被消失。
我们可以看到这棵科技树在OpenAI的旁边又长出了一个分支,有一帮人想要用更高的算力,但也有一帮科学家、从业者、技术极客说千亿参数可以涌现智能,百亿参数可不可以?
所以,在LLaMA出现以后,整个开源社区开始百花齐放,小参数模型的性能快速崛起。
我们可以看到,有些百亿参数在某一些能力上已经接近了GPT。我们突然发现,也许千亿参数不是唯一选择,这个分支带来了AI大模型的二元化。

我当时有一个演讲说,有经济实力的公司全在卷算力,他们的梦想是造出一个爱因斯坦,再解决几个物理定律。还有一帮开源社区的极客爱好者,用更小的资源、更精巧的算法去实现智能,所以当时提出平民化大模型,每个人都可以随便用的大模型。
所以,我们发现用百亿参数的模型,加上客户自己的私有数据,再加应用的打磨,在专业领域可以约等于千亿参数大模型。
千亿参数大模型全面性更好,它的涉及面很宽,但在企业场景当中,只要在一个专业点上做好就可以。所以专业就够了,并且更具性价比。
三、每个企业都有私有化大模型的时代,
来了!
百亿参数足够,成本又非常低,所以每个企业都将进入私有化大模型的时代,任何企业都可以有自己的大模型服务器。
我们来看三个时代的企业核心变化。
最早的工业时代需要土地、厂房和生产线,这是核心资产。
到了互联网时代,谁有流量谁就牛。
最后一个阶段就是经营数据的数智化,AI的出现使得数据的价值放大。
在以前数字化的时代,基本上是表格里的数据,必须被数据库存储,这时候只是阿拉伯数字,但AI出现后可以理解自然语言,使得所有的会议纪要、邮件、讨论决策过程都变成数据。所以经营的全过程都是数据,这些数据有可能通过AI的参与变成公司的决策竞争力。
1.大模型到底能做什么?
AI在企业内部到底能做什么?很多朋友跟我说好像就是汇报或者写一个段子,或者用别的大模型做一张,这导致很多人感觉不太需要大模型。
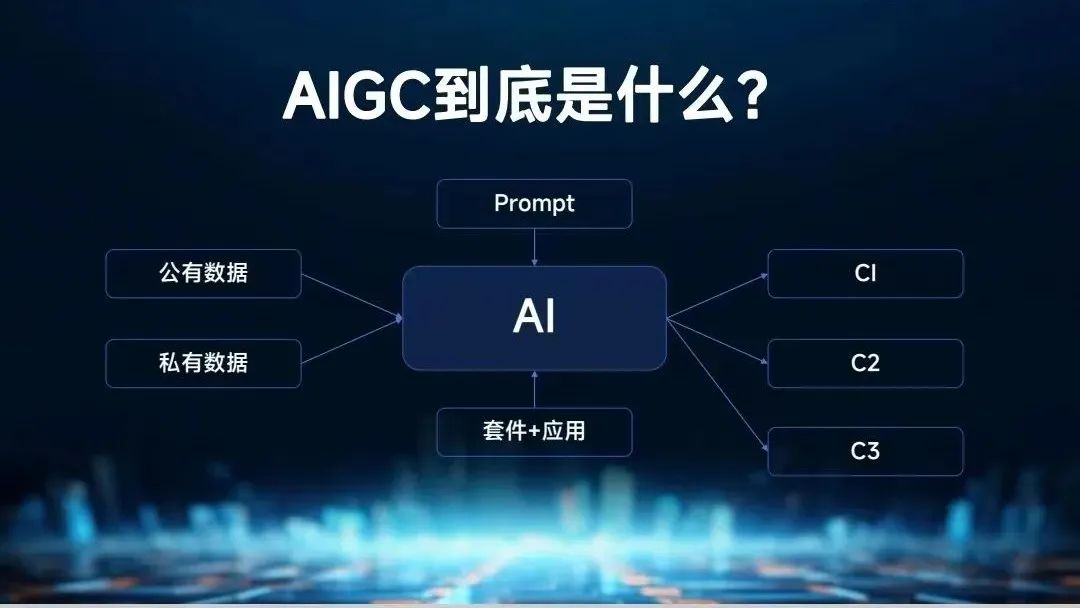
在阐述这个问题前讲一下什么是AIGC。
AIGC就是AI生成内容,但如果把这个过程放大来看,AI由数据训练出来,如果是互联网出版物的数据,它对知识的了解就是大家的常识,之后给它一个提问,那就可以产生内容(C1),这种内容的实现回答都正确,但是没有用,因为很表层。
如果可以结合企业的私有数据,那就可以产生专业知识的内容(C2),如果可以根据私有数据再配合强应用,配合整个套件,实现企业经营决策的全流程(C3)。
那么可以把企业对AI的使用,总结成三个段位:
第一,青铜。基于公有数据,使用AI和Prompt,生成一些宣传文档或。
第二,黄金。例如公司有一个行政文档,员工守则、请假条例,把它灌到大模型里,问它来公司一年,想请三天假是否可以,或者明天要出差去太原,根据公司的差旅标准,住宿可以报销多少钱,这一类就是今天被行业内广泛提的“数字员工”。
第三,王者。这是对企业全过程的经营数据由AI参与,使得AI可以直接给你提经营决策。比如今天该不该发布一个产品,哪些费用可以减少,哪一个地方的工作重点需要加强——企业最大的成本不是用工成本,而是经营错误的成本,是对经营不够了解导致决策失误的成本。

所以,企业要想真正用好AI,应该是全流程、全数据化,完成“数字老板”,可以理解企业各种经营细节的Copilot,帮你提出经营决策建议,这件事情必须做到真正的流程重构。
2.OpenAI的“阳谋”
在展开前,调侃说一下OpenAI的“阳谋”,也就是你知道这件事可能对你不太好,但是你拒绝不了。
两千年前汉武帝想要分封,诸侯太大,汉武帝不容易打得过,直接杀人家会造反,于是有一个千古阳谋是推恩令,诸侯的土地平均继承给你的儿子,生几个分几个,随着诸侯一代代每个人得到的军队和土地越来越少,这些诸侯自然而然消失了。因为这是推恩令,诸侯无法拒绝,这就是阳谋。

OpenAI今天几乎已经把互联网上所有公开出版的数据读取了,但要知道人类的知识体系,互联网再浩瀚也是人类知识体系的冰山一角。比如开会讨论找重点的过程,实际是没有出版的。
因为一个公司的文档都有自己的竞争力和特点,哪怕在邮件、开会讨论的事情,其实都有几十人、几百人组成的共同的人类决策系统,这是今天OpenAI没有的。
所以,OpenAI推出了GPT Store,开发者通过它可以很快构建自己的应用,但这个东西一推出,就使得OpenAI以前只会从互联网上抓取数据,变成GPT Store,在内生的平台上产生数据。
因为它需要的是整个决策流程和推理能力,我们通过一个个GPT Store,实际是给它贡献更多的决策数据。调侃一下,都说Apple Store是交苹果税,GPT Store交的是智商税,因为大模型可以学习,可以把这些数据都变成自己的内容。
如果一家公司要实现经营数据的全流程AI化,只靠合同、财务,短期内肯定可以提高效率。但当推出AI的时候,财务部跟我说,财务报表如果AI化,哪天泄漏都要被抓起来,法务也说合同怎么AI化,最后发现所谓的重要部门都有足够的理由抗辩。
如果我们使用ChatGPT,可能在帮自己的竞争对手,甚至有可能使得ChatGPT具备你的能力,某天就变成它的一个API接口,这件事正在发生。
GPT Store发布的时候,一位硅谷创业者说,Altman给了500美金的ChatGPT优惠券,但是毁了300万美金的公司,因为它把创业者做的事给做了。
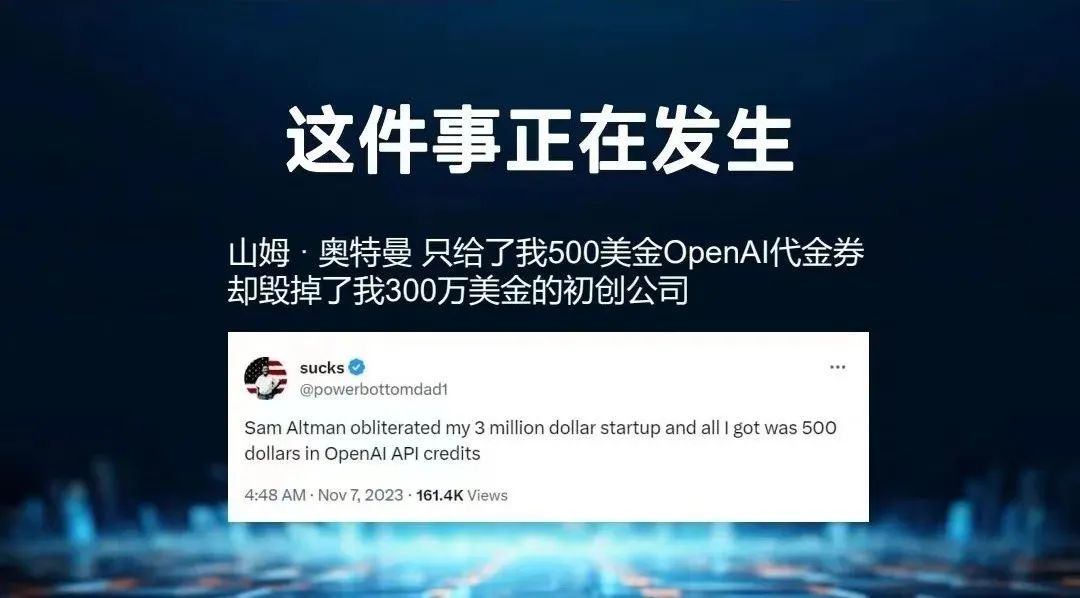
前不久OpenAI内讧,有一种说法是GPT Store的推出在内部有争议,有更多内生数据进去的时候,人们不知道大模型未来到底会长成什么样。
我看过Altman的采访,他说以后人工智能应该变成:跟他说我要成立一家万亿美金的公司,人工智能开始分析市场的各种情况,创建创业计划,在网上找人力简历,发邮件雇人买东西,过了三年,整个公司运营起来,一看市值一万亿美金。
他说,以后95%的人都不要工作,5%的人工作就可以,给你们创造足够的财富,天天吃喝玩乐挺好的。
3.私有化大模型,增强企业竞争力
最初我也有这样的恐惧,但今天认为不是,刚才讲的科技树,在大的千亿通用模型边上,又开始出现百亿参数模型,最近还出了几十亿参数的模型,通过各种算法也能实现效能的增加。以后,每个人就有了贴身的助理,数据都是你自己的。
所以,企业要有持续的竞争力,就应该使用私有化大模型,让经营数据内循环,让企业过去留在每个人脑海的经验变成整个决策智能的一部分。
再回顾一下,企业要实现AI的王者地位,就应该是全过程的经营数据都变成私有化大模型的一部分,再加上强硬套件,实现数字员工+辅助决策,这是我通过不断跟客户的讨论和打磨,通过全员AI深度应用总结出来的模式。
四、脱离应用,大模型再好也只是技术狂欢
七年磨一剑,因为我们在AI行业投入很久,现在有顶级的团队。我们几年前就开始尝试各种算法,当时买了很多服务器、训练很多大模型,所以对算法的理解没有问题,还有是数据累计,其实在语音文字的语料上也累计了好几年,最重要的是中间两个:场景认知和应用打磨。
我们今天发布的大模型,专为企业应用而生。我们训练140亿参数的大模型,在企业应用的专业场景可以实现千亿参数的效果,我们在发布大模型基座的时候,直接做了7个应用方向的微调,也就是大模型发布基座的时候不能用。
比如前不久开复老师发了34B的模型,我们给他做了聊天微调,里面有15万高质量的数据,所以我们发布微调版本,在很多榜上名列前茅,现在还有很多爱好者说猎户星空调得不错。
因为要调好一个模型的应用方向,要在这个方向上积累非常专业且高质量的数据,并且我们还提供一个目标叫做千元显卡即可运行,今天也做到了,所以总结为三个词:用得好、用得起、用得安心。
看性能要先看榜单成绩,说一句题外话,对中国大模型来说,榜单刷分很容易,因为很多测试题是公开的,让大模型有榜单的训练数据,那就可以得很高的分。
如果让大模型读过这些题再参加评测,的确可以刷出更高的分。但我跟团队说,不能用应试教育版去发,就发一个没有读过题的版本,所以发布“素质教育版”。
这个素质教育版本基座能力,在200亿参数以下所有大模型的评测体系上得分都是领先的,这就代表比较强的基座能力,犯错的几率会很小。
在综合评测机构OpenCompass的测试中,我们比720亿的千问得分略差一点,但700亿以下的,我们的得分都是最好的。
这意味着我们大模型的基座能力,能够在企业应用当中平替掉很多三四百亿参数模型,参数可以简单理解成网络复杂度,百亿参数的模型,比千亿参数可以省90%以上的私有化部署成本。
另外,猎户星空可以支持320K的Token,一个Token相当于1-2个汉字,可以一次性读取50万字的文档,经过我们的实测,对30万字的文档里的任何一句话进行提问,它全部可以回答出来。
最早的时候大概只能支持千字量级的文档,文档过长的话,需要做大量的匹配工作。而现在,相当于一本几十万字的侦探小说,让它读完之后,问它杀手是谁,它立马能回答出来。
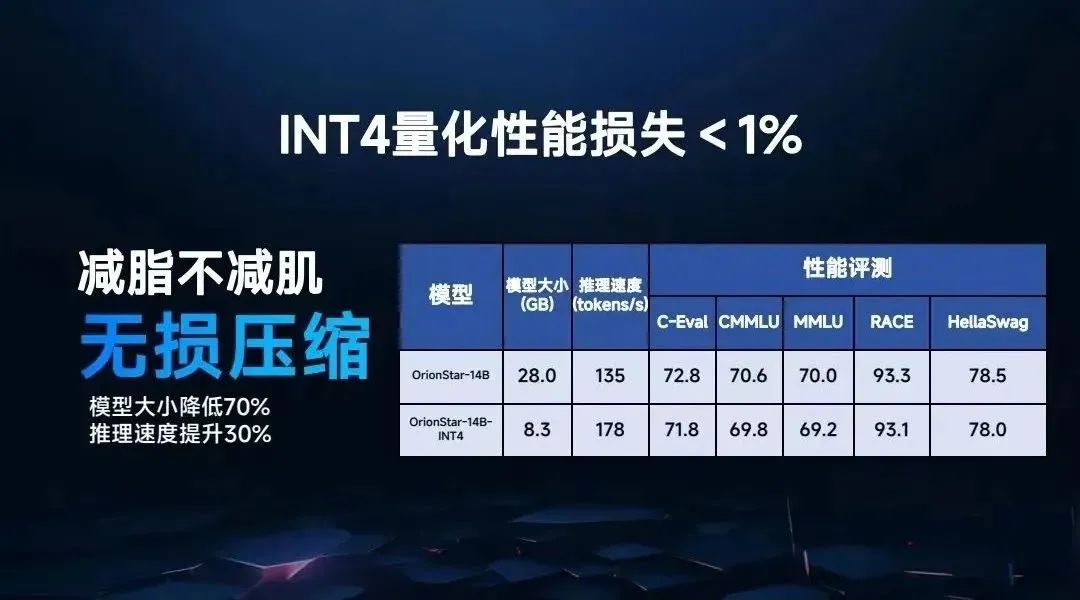
可以说,这是非常厉害的特性,量化性能的损失低于1%。把它的模型缩小到原来的几分之一大小,它依然能够实现原来模型99%的性能,我们把这叫作“减脂不减肌,无损压缩”。模型大小降低70%,推理速度却提高30%,这意味可以用非常便宜的显卡运作起来。
简单来说,一块英伟达的3060芯片就能跑起这个模型,大家知道3060芯片是什么价位吗?1500元。这意味着百亿参数模型,第一次能够在千元的显卡上几乎无损的运行。
所以,为什么说企业的私有化大模型时代到来了,因为你的服务器成本和运营成本会降到你几乎可以忽略不计。
除了以上的优势,我们还加入了日、韩语能力测评。
以前我们做服务机器人的时候,每进到一个餐厅就得做适配,这让我们很苦恼。以前,在海外销售的服务机器人不具备多语言能力,很多可能性被钳制住了,现在有了大模型,日语、韩语可以做到很好的交流,能够进一步扩宽市场。
在评测指标上,今天发的140亿参数的猎户星空大模型是所有200亿参数以下各项评测性能最好的,但是跟GPT的全面性仍然有一定差距。
不过,通过各企业应用定义好垂直场景,通过数据和应用的打磨,我们已经实践出在应用场景上超越GPT-4的可能性,这不是妄想。
五、下一个里程碑:专注百亿模型
今天发布了这个大模型,我们下一步准备怎么做呢?
我们依然不会去训千亿的大模型,因为我认为这个基数的能力够。有人说千亿大模型的基数不断提升怎么办?条条大路通罗马。
最近业内开始出现一个叫MoE的构架。所谓MoE构架,是用多个模型进行集体决策,完成对一件事情的判断。
今天在业内发的论文里,8个百亿参数模型的联合运行,其性能的某些指标已经超过了GPT3.5。相当于很多火箭都在打造一个更大更强的发动机,SpaceX做了一个核心的发动机,绑成9个就是猎鹰9号,绑成27个就是猎鹰重型。
它用一个极简的可复制的构架完成了最大载送量的火箭,而不是去从头造一个特别独一无二的发动机。猎户星空正在做同样的事情,专注在百亿参数模型的性能提优,保证通过新的构架完成基础能力的不断提升。
为了让企业更好地应用,我们独家推出微调全家桶。微调指一个基座只有技术人员可以使用,这个时候就要有一个微调方向,去解决这个问题。我们做了一个聊天的微调大概用了15万条高质量的数据,有的是发完了以后再做的微调,有的时候是自带的插件微调。
大模型要和传统的程序有一个接口,这个接口调用一个插件,我们也针对插件做微调。除此之外还有专业问答,通过微调进行大海捞针,之后生成。
这些方向基本上都是我们通过不断实践、和客户摸索出来的。微调只是相对大模型的预训练为“微调”,但是工作量并不小,而且哪个数据能够让大模型表现更好,都是一点一点打磨出来的。
8个方向里面,我们重点打磨的两大方向,叫做RAG和Agent,这是在今天大模型AI浪潮里非常重要的两个方向。
RAG即专业知识问答,它更学术化的名称为“检索增强生成”。
比如,当你问大模型:“为什么周鸿祎先生要穿红色衣服?”如果没有做RAG的检索增强,他可能就会说:“因为可能他喜欢红色”。我们看过各种原因,包括“他喜欢红色”、“红色是他的吉祥色”“今年是他的本命年”等等,这些结论是它根据泛知识做的大致推理。
而做了检索增强以后,它会根据背景信息去重新生成检索,给你一个正确的回答:因为他的名字经常被人读成“周鸿伟”,他穿红衣是为了提醒别人他是“鸿祎”。
这个回答他曾在几次演讲当中说过,但是不一定是互联网上的公开数据集,因此如果没有检索增强,就很容易出错。
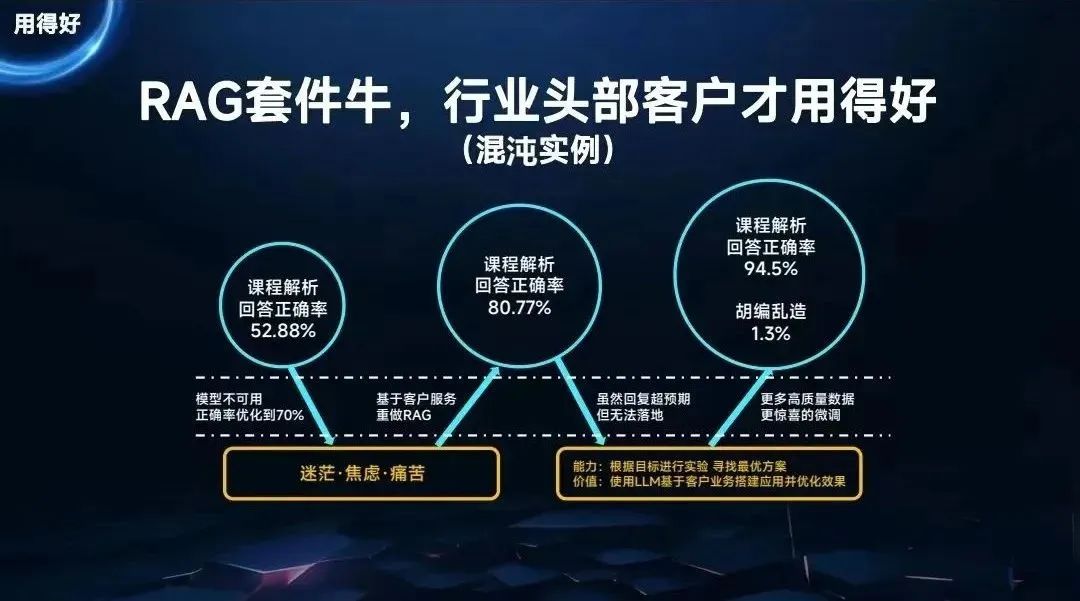
RAG被很多行业人反复提及,并且有了专业术语。但是真实的情况是,如果你不深入做,虽然很快可以给别人Demo,但是半年都用不好,因为将准确率把控好非常困难。

今天开源社区有很多RAG套件,基本上往上一套之后再把文档一换就可以回答了,但是这个回答往往准确率不够高,而我们这次推出RAG套件是一系列的组合,能够保证极高的准确率。
我们在内部做了一轮评测,准确率远远高于对手,这不是大模型基座单一的能力,而是与RAG套件统一合作完成的。
有一个概念叫“数字员工”。但是,目前的数字员工能力很低,基本上就只能对文档给出提示。要想真正地将企业应用与专业知识深度融合,做到和人一样准确的回答,需要RAG套件。
Agent是硅谷今年特别火的方向。它帮助大模型实现人类的记忆、行为规划等等一系列的事情。Agent用得最多的场景是和传统的系统接口之间调一个打开接口。
这件事听起来很简单,但是并不容易。因为大模型常常回答不稳定,如果不做足够多的微调,问它同一个问题就会出现不固定的答案,或者难以从一句话里找出关键点。
在Agent所需要的五种能力中,猎户星空大模型均接近GPT-4的水平,其中包括:意图识别成功率90.3%、首轮抽参成功率100%、多轮抽参成功率90%、缺槽反问成功率91%、插件调用成功率91%。

虽然我不是很懂专业领域,但是我知道这些很重要。因为要保证大模型跟你的系统接口不出错,保证大模型能够稳定运行,就需要套指标。我们评测过很多同等参数量的模型,能够超过70%都很难。
比如我问:“北京今天天气怎么样?”它得知道你问的是天气,还是北京的天气,而且每次保证足够的稳定。我们最近想要把我们的经营数据和大模型打通,这套工作程序非常复杂,但是能够稳定输出,因此需要试一试。
综上所述,要先把RAG和Agent两个套件用好,企业数字员工才能够落地。否则用一些公开接口、一套开源数据库、开源向量数据库或构架去提升准确率的话,完全没法应用。
六、借助AI,如何打造“数字老板”?
我们这次发布的1400亿参数大模型,完全开源免费、可商用。
之后,我们还会成立免费的社区支持群,将微调应用方向开源,以此希望促进大模型行业不再只是技术狂欢,而能够真正落地,我们甚至期待更好的技术大模型的出现。
猎户星空百亿参数大模型,我们认为它是企业标配的首选,值得企业们为我们驻足。
通过以上的讲解可以看出,我们的产品差不多算是达到黄金段位了,但是还未登顶王者段位。不过,我们正在走向王者的路。
真正要实现王者段位,就要让AI要和企业的经营数据全绑定,一步一步深入,为企业提供决策支持。我们当时提出了一个叫AI基地的概念,AI产生决策,而不是内容,一个企业要真正到达王者段位,需要AI辅助决策。
为此,我们推出了一个强应用套件——聚言。聚言专门用作咨询服务,当企业或员工遇到难题时,它可以教课、做培训,它帮助企业老板提高决策效率,增加企业决策准确度,是一种真正意义上的“数字老板”。
我们做了三个重点的强应用,在这几个强应用上还提供保姆式的服务,真正通过应用+调试+流程整合一条龙服务,全程帮用户进行落地。我们专门参考传统咨询公司的做法,提供的服务包括从业务流程如何组织体系改造,到方案设计、大模型的选型、实施、培训等。我们提出交钥匙解决方案,保证AI的应用效率可以做到行业领先。
虽说基础模型和模型工具大家都有,但在今天再回头看,跟着应用一起生长出的几个套件才应该是真正的重点,而这套解决方案是跟客户一起打磨出来的,不是在办公室里想出来的。

其实,AI不是一把手推动,就没有办法真正推下去。而AI真正的提效不在于数字员工,而是老板,老板的效率高,整个公司就活了。
杰克·韦尔奇说:“老板是最后一个知道公司要倒闭的人。”其因为很多经营的细节是散落在很多地方,只能通过一个个人的汇报了解总体情况,而且听汇报的效率和精力都是有限的。
接下来,我有三个问题问老板们:
1.你真的听得到一线的呼声吗?
HR一直是很难数字化的部门,因为在大模型出现前,每个人的工作是通过文字表达,所以过去任何系统很难真正做到对员工工作状态有足够了解。
我想今天对一线员工的理解,很多人工作很辛苦,但并不知道他在忙什么。整个公司都在做战略项目的时候,可能到了一线的时候,很多人都没有在做。
我琢磨这个产品的时候在想,真正帮企业提效,一定要找到AI比人擅长的地方,而不是简单替代人。
AI真正比人擅长的地方是可以读数千份文档,做出归纳总结,它的广度和精力一定比人强,它做出基本的推理给你提供决策支持。
2.你公司的运成本花到哪里了?
猎豹移动出海是当时亚马逊在海外最大的中国客户,所以我们很早就对亚马逊云在全球的部署深度参与,当我们的海外业务遇到阻碍的时候,把整个云的运维队伍分拆出来成了一家公司,帮助各个中小企业和出海企业上亚马逊云和谷歌云,但就这一个业务,它的复杂让我听不懂。
后来发现这是极其深度的工程师,它的语言对外几乎无法交流,CEO不懂云,CIO不敢得罪CTO,业务部门总是申请更多的云资源,但很多时候都不怎么用,CIO又不了解业务的细节,所以云就变成闲置资产。
今天云资产已经成了全公司的重要资产之一,所有的企业都是科技企业,所以云资产的管理也是一个痛点。因此我们在上面开发了针对这项功能。
3.你的新营销策略怎么做?
今天要去得一份咨询报告非常贵,如果问一下ChatGPT,他回答听起来有用,但它很难生成长达几十页的报告,实用价值并不大。
为此,我们做了几个Agent互相讨论的工具,可以给出一些营销策略。
聚言希望打造的就是老板真正的决策助手,我们希望可以让AI进入全流程经营决策,但它并不是简单的实施,而是需要跟客户一起生长。
七、2024,对AI的3点预测
最后一部分,我想对2024年的AI做三点预测:
第一,千亿大模型真正使用起来很少,但私有化百亿大模型会百花盛开。相信更多的企业会部署私有化的百亿大模型,真正帮助企业经营提效。
第二,超越OpenAI的机会来自应用创业公司。
今天很多朋友去美国看回来跟我们聊,说这一波AI的应用创业硅谷实在太火了。
回想Web时代的互联网创业,中国可能和美国是1:1,但是这一波AI创业硅谷至少是我们的好几倍,硅谷已经有了AI应用一条街,那条街上都是AI创业公司,他们将大模型的能力和真正的实际相结合,让AI能真正落地。
第三,数字老板成功企业标配。
以后董事会考核CEO使用AI的时长,如果一个CEO用AI都用得少,我觉得你是不是数字老板不重要,你一定会落后于这个时代。
另外就是,具生智能现在很火,但是人型机器人毕竟不能量产。
我们要创新,但是我们也要务实,我做机器人这个行业也做了七年,和机械相结合、传感器相结合的时候,整个进展难度没有摩尔定律的支撑,必须在机械结合上做大量的改进,所以非常难。
大模型今天对语言的理解,对企业内部的应用还需要一些成长和落地,更不要说变成了一个能够自主去熟悉物理环境的人型机器人。
我们今天把这个亮点回顾一下:
首先,我认为科技创新的核心是Think Different,在原来的路径上,我们或许可以做得更好,但对手也可以做得更好。
我们今天看到的科技爆炸不是一条通天的登天梯,而是不断的竖状结构。当这条路被别人占领的时候,你就可以想另一条路,也许就能实现新的创新。
这就是创新的逻辑,你在一条路上卷不过别人的时候,可以想另一条路,这条路也许也能实现超越。

这就是又一次的Think Different,成就了一次又一次的创新,所以我坚决不相信只有一条路才能成功,我们每一个科技创业者都应该去找到不同的道路实现差异化的创新。
第二,我们在业内首提企业应用AI的三个段位:从青铜到黄金,再到王者。
接一个API让员工用用大模型只是青铜段位;能够深度的使用RAG套件、私有数据相结合、实现数字员工是黄金段位;第三个段位应该是企业经营全流程AI化,实现AI的辅助决策,帮助企业提高决策效率和准确率。
而猎户星空大模型,也希望各位企业成为AI应用的王者,也希望所有的企业都知道创新道路千万条,不是只有OpenAI这一条。
最后我想说,这是我有史以来准备最充分的一次演讲。今年讲七年磨一剑,实际上七年时间都在探索。
2016年,当我喊出应用AI的时候,很多人问我你干嘛不去做电动车。但我生来倔强且坚持,既然选择了就决定一路往前。我一直热爱AI领域,中间有很多人质疑我的选择,我从选择的那一天起就决定不要轻易放弃。
但是,创新是很孤独的路,我相信你们大家也有过心碎、焦虑的时刻。
我觉得人生有的时候就是,你既然选择了就是一路往前。
前段时间我骑着共享单车在路上,突然脑海里意识到,我以前也走过这条路。我今年45岁了,如果我遇到以前的自己,我会跟他发生怎么样的对话。
17岁的我,特别热爱计算机,每天去读各种计算机书籍,所以最后有机会走向这条赛道。如果遇到17岁的我,我会跟他说,你一定要保持自己的热爱,往前冲。
27岁的我,工作特别玩命,有段时间住院,且对健康产生焦虑。如果遇到27岁的我,我一定告诉自己,你肯定觉得压力,但是不要被压力所控制,恐惧不会带来任何价值,你只有全力以赴。
到34岁的我开始创业,那个时候我们团队非常小,但我想清楚应该Think Different,应该找一条不同的路,不应该在过去的战场继续留念,所以做了出海。如果遇到34岁的我,我想说,放下自己好好做你热爱的事情,你一定能够再成功。

那段时间特别感触,生活中只有一种真正的英雄主义,你认清了生活的真相以后依然热爱生活。
后来我想,管那么多呢?外在世界我也变不了,我就好好的改变自己。我既然做了AI这件事情,就要保持对他的热爱。我是一个做产品的,我就应该热爱产品、热爱应用,只要用热爱,就能在创新的道路上一点一点摸索出自己的道路。
Think Different看上去很容易,实际却很难,失败的风险也很高。
我们看到的创新成功案例,是无数个创新者、创业者在不断寻找方法,前仆后继失败的人之后冒出的那几个人。我们不一定可以成为最终冒出头的人,但是要做一往无前的人,因为每一份的努力都有意义。
最后,猎户星空的私有化大模型,希望与每一个热爱创新的创业者一起乘风破浪,谢谢大家!
来源:笔记侠