
本文整理自北京线下公开课,演讲人:姜頔,易车网数据分析专家,演讲主题:《增长的常用模型》。
大家好,我是易车网的姜頔,今天我给大家带来的分享主题是《增长的常用模型》。
今天的分享主要分为以下六个部分:

一、自我介绍
我在早稻田大学读完硕士后,在日本的一家地震研究所做地震分析员。在此期间,我用过一些土木工程类的软件,也用过一些数学分析的软件,像现在大家都用的MySQL,Excel,还有VBA这些。
现在,我在易车做数据分析专家,我们平常涉及到的业务除了普通的数据提取、分析报告,还有就是模型,比如渠道评估模型、易车作者评分模型、用户等级模型、召回模型等等。接下来我也会挑几个我们用得比较好的模型跟大家分享。
先说一下我经历的增长经验。
第一个是配合渠道投放,达到DAU同比增长300%。我们现在的平台是百万量级的DAU,这说明什么情况呢?增长300%,这说明我们花钱了,肯定是花钱才能增长。
但是花的钱值不值得?花没花在刀刃上?这就是第二个,新增用户30日同比留存提高了3个百分点,这说明我们花钱真的是花对了。
第三个是构造成交模型,这个成交同比增长了9倍。
这就是我主要的一些增长数据。
二、易车的现状与挑战
关于易车,我们今天主要分享这四个词:老、新、惨,还有挑战。
第一个为什么是老呢?
我们的老程序员写东西都是用.net,但现在.net好像已经不时兴了。现在大家出厂全都自带的JAVA,大部分新人看不懂原来.net那些东西,以致于很多东西都得推翻,再拿JAVA重构一遍,从这个角度你也可以看出易车的老。
“新”又是什么呢?
去年易车开始经历品牌换新:
新的面孔,从各个领域吸纳了新的大咖;
产品的快速更新,自杨永峰总上任以后,最慢两周更新一个版本,在这个版本的更新期间还不断的做 AB test;
还有一些新技术的开发应用,像机器的写作,智能聊天等,这都是新技术的开发应用。
然后是“惨”。
金融惨大家都知道,都没钱了。互联网早就进入下半场了,不像上半场“人傻钱多”。现在大家都在关注转化率、曝光率等等,拿指标去考核,这也说明互联网已经进入了精细化运营的阶段了。
而汽车行业的“惨”要怎么说呢?
也是政策等的一些原因。我自己有个例子:我11年10月份去的日本,我父亲在11年9月份把我们家第一辆车卖了,后来紧接着11年12月份开始摇号,11年那辆车连车带牌卖了6万,现在你买一个车指标15到20万,这就是政策的影响。
几个因素叠加之后共同制约,互联网汽车就更惨了,但这就是现在的状况。大家都在收紧,都在说汽车寒冬到了,这就是“惨”。
最后一个是挑战。
这个行业前有汽车之家,后有新进的懂车帝,我们怎么在这个圈里形成自己的壁垒,还能创造新的玩法?刘晓科总说过一句话,战争拼的不是人数,而是谋略,要以“奇”招制胜,你烧我粮仓,我炸你军火库,这才叫打仗!
这就是今天的主题:增长的三大流派。
三、增长的三大流派
增长的三大流派是怎么回事?
黄天文老师在他的书里将市面的所有增长分为三大类,第一类是市场营销派,第二类是实验增长派,第三类是技术派。
我在这三大流派里分别选了三个模型,分别是:市场营销派-渠道评估模型,实验增长派-用户召回的模型,技术派-逻辑回归,促成交的模型。这三个模型又分别对应的是三个用户生命周期,分别是拉新、流失与促活阶段。
渠道评估模型就是花钱买流量,用这个模型买不到吃亏,买不到上当。
用户召回模型是从发现问题、提出想法、预期效果、测试矩阵、复盘分析这五步教你如何上道。
至于最后一个逻辑回归,增长黑客真的是可遇不可求么?我们分别来看。
四、市场营销派-渠道评估模型
1.渠道质量评估模型
我做了一个渠道模型,老板经常会问某个渠道质量怎么样,我们该怎么去回答?什么是质量?是留存?成本?还是数量?其实这些东西都要考虑。
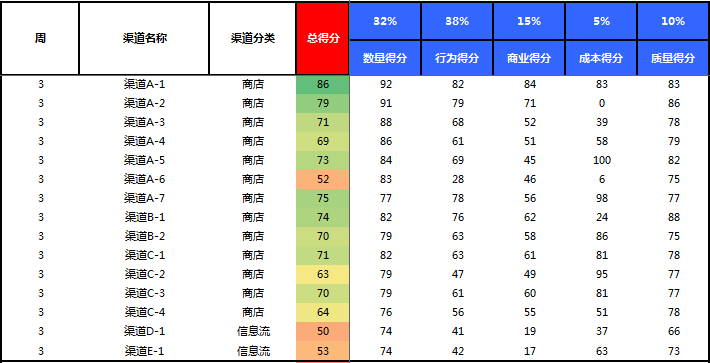
上图模型中的红色总得分这一列是汇总总得分,旁边蓝色的分别有数量、行为、商业、成本还有质量,这五个是一级指标,上面是权限,通过标准化,我们把这个得分再乘以它的权重,最后算出来是总得分,这个总得分就是反映这个渠道的质量。
相当于我们高考的语数外等等这些学科相互独立的指标,共同制约着我们最后的总得分,通过总得分反映出这个学生是否全面,就是这样一个模型。
权重怎么分配呢?权重分配有一个AHP层次分析法非常好用,稍后我会重点去讲。
还有一个问题,在市面上常用的评估模型大体分为回归和标准化两种模型。为什么我们在这里要用标准化,而不是回归模型?
其实这两种模型我都做过,但标准化模型能够最快地去反映出我们在不同阶段的指标。比如我们在增量期,数量这个权重就比较高。如果在存量期,相对于它的质量,以及留存,还有商业转化的要求会比较高,在不同的时期我们能够快速更改权重,实现策略的转化。
2 .建模过程
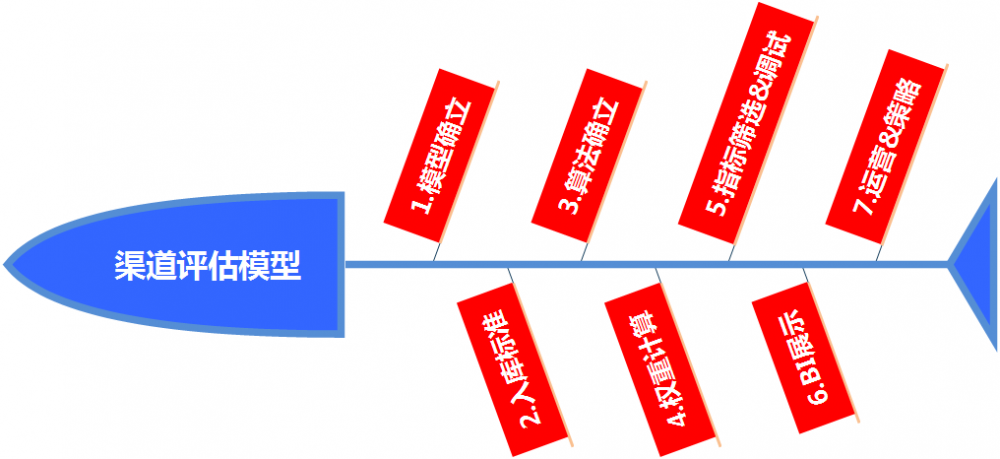
上图是建模的过程,分为七步。四、六、七会在后面重点去讲。
首先是模型的确立,刚才已经给大家说过,我们选用标准化。
然后是入库标准,我们这个模型什么样的渠道才能去入库?是所有的付费渠道还是说所有的渠道?我们这里选择付费渠道。
新增是否有阈值呢?是只要这个渠道有新增就进入到模型里面,还是说有100人、200人、500人的阈值呢?我们选择付费的渠道只要有新增,我们就会进入到模型当中。
第三个是算法的确立。标准化的算法其实有最小、最大值,还有最标准化等等,我们这里选用最小值和最大值标准化。
第四个是权重计算,AHP层次分析法。
第五个是指标筛选。这个涉及到降维、剔除还有整合变量,就是我刚才说的,你这个指标要相互独立,跟其他的指标相关性要非常低,能够完全代表你这个平台。
我再举一个例子,假如说语数外三科能评判一个用户的好坏,然后非常全面。但如果你这个语数外三门换了,换成一个高等数学、线性代数、复变函数,你把这三门给加在一起了,这三门的总分,只能说明这一个学生他数学学的好坏,你不能评判整体的。所以这个指标筛选也是非常重要的,是相互独立,相关性非常低的指标。
第六和第七是BI展示和运营策略,这个后面我会具体去讲。
3. AHP层次分析法
现在大多数的权重都是拍脑袋计算的,包括有些KPI的权重都很随意。其实这里有一种非常好用的方法——AHP层次分析法。这种方法怎么用呢?
AHP层次分析法
标度尺1、3、5、7、9
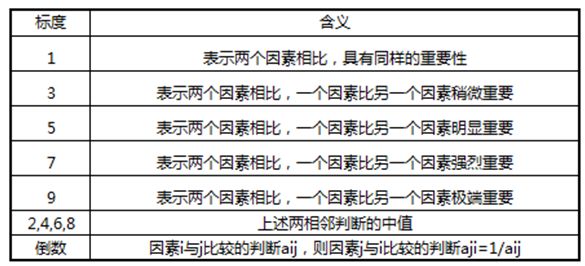
上图有一个标度池1、3、5、7、9。这是什么意思呢?
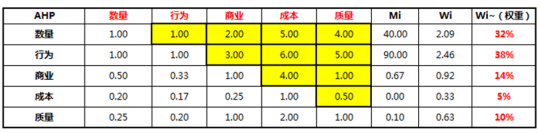
我们通过两两指标相比较,如果A:B同样重要就是1,稍微重要是3,明显重要是5,强烈重要是7,极端重要是9,其次2、4、6、8是中间值,依此对比,数量和行为同样重要是1,数量比商业稍微重要就是2,数量明显重要于成本就是5.
依此类推,我们把这个数字填到左上黄色倒三角的模型里面,这就是AHP层次分析法里面矩阵模型,就能得到它的权重。这个(AHP层次分析法)可以在网上下载。

通过两两比较,将你的层次定性和定量分析,最后输出权重,就进入到下一步模型的骨架,就这个总得分。
一级指标设好了权重,同样这儿有二级指标,也类似于这个方法,把所有二级指标的权重设置好,有权重,有指标,最后进行标准化,获得一个得分。这也就是我刚才说的,它在不同的时期权重不一样。
你看我们现在在数量和行为的比是1,数量和商业是2,数量和成本是5,数量比成本,就是我们认为成本不是很重要,数量是最重要的时期,我们的权重是这样。
如果在年底,要求数量增长的时候,权重可以这样分配,但如果在淡季时候要保量,求质的情况下,我们对于商业得分就应该是比数量重要,依此类推按照不同时期,做出相应的权重调整。
4.BI展示和策略
BI展示其实特别重要,在正常的情况下,数据的提取,数据的ETL,以及数据的清洗这一部分,会占据我们90%的时间。但是它只有10%的价值,而领导看这个数据,只用10%的时间,却会贡献90%的价值。
在承上启下的过程中最重要的一步就是BI展示,不要小瞧BI展示。
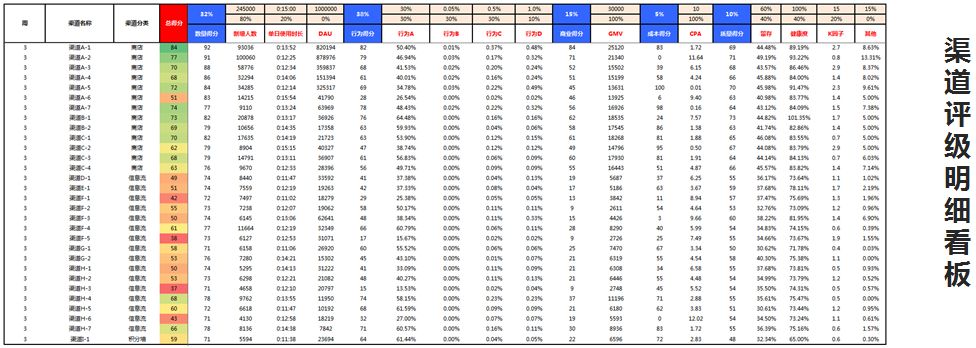
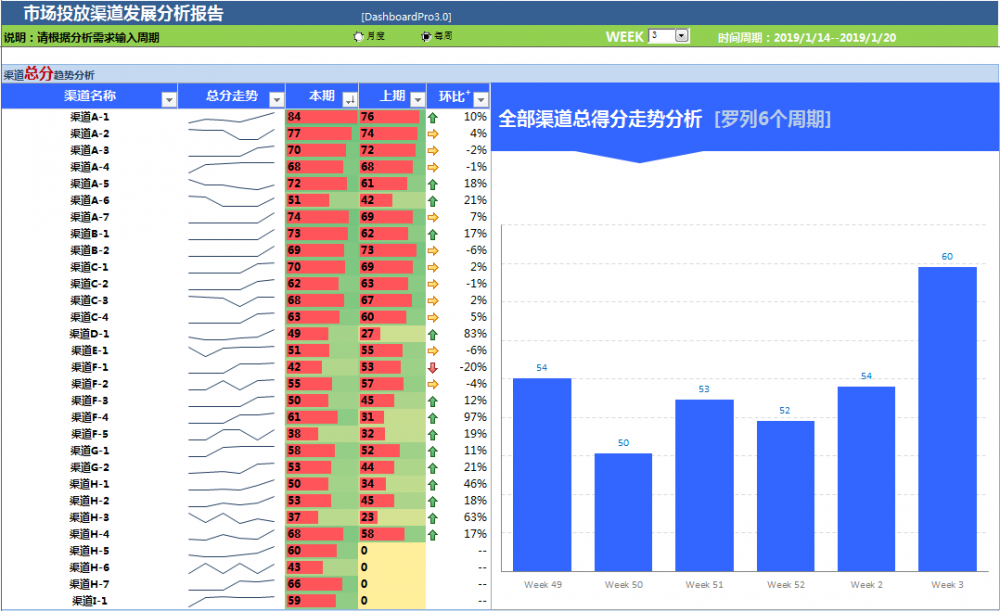
看一下上面这个渠道评级明细,这就是渠道评估后得出的总表,给boss看,要绝对值有绝对值,要权重有权重,然后它的一级指标、二级指标、上限值等等都在这张表里面可以汇总。
通过这张表老板们可以看出很多东西,像安卓的应用市场,比如vivo、OPPO、华为,他们有一个最大的属性,就是它们增量会有瓶颈。但是它们的质量特别好,不论是留存还是用户分享动作都非常好。
像信息流渠道,比如快手、抖音这样的,它们的量非常多,而且商业转化高,这取决于你要怎么投放素材。如果你投放的素材是激励用户去购买新车、二手车的,就会提高我们的成交转化率,这些渠道的不同属性都可以通过这张表表达出来。
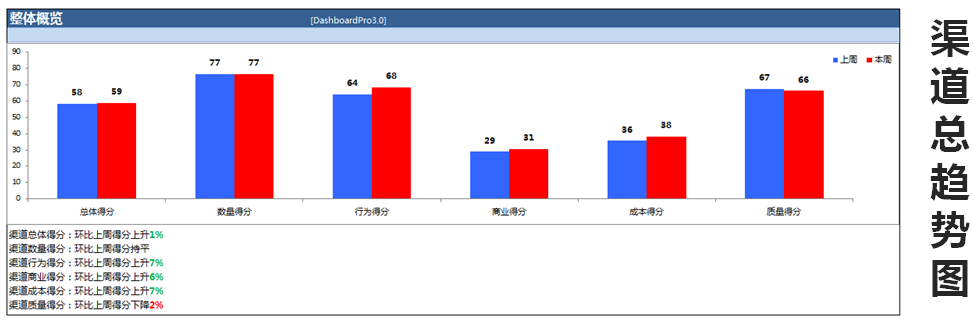
看一下这张渠道的总趋势图,在这个总趋势图里,我们把所有渠道的表现都汇总成一张图,它有一个总得分。
这个图其实就相当于咱们买基金、买股票时的沪深指数、大盘指数,我们可以通过渠道总得分来看产品。我们的产品每周进行更迭的时候,需要知道是产品对它的影响比较大,还是更容易受大盘的影响?
比如春节时期是洗车、买车的高峰,你不用额外做什么,它的自然量就会涨上来,因为大家逢年过节普遍有用车的需求,这就是大盘因素。
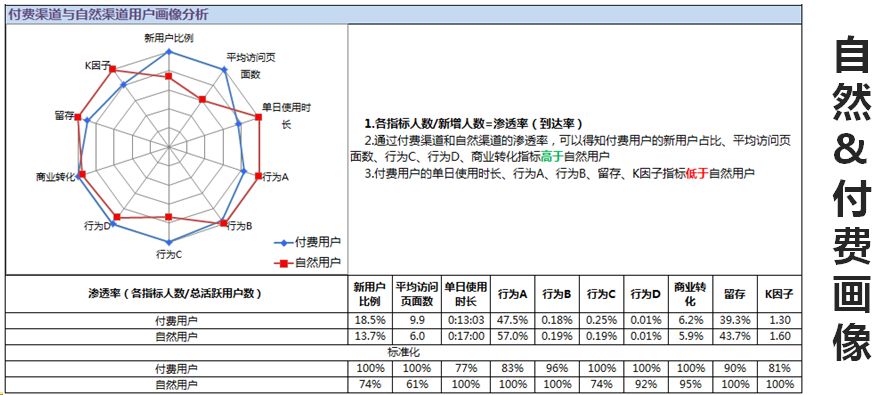
最后看一下自然&付费的画像。由此衍生出自然&付费画像的对比,自然用户很大程度来源于我们的品牌宣传,具有很高的不确定性,但是跟品牌宣传是直接相关的。付费渠道大多数就是渠道拉新,通过这张表可以看出品宣和渠道这两个用户的属性。
市场营销派模型讲完了,我们再来看实验增长派模型。
五、实验增长派-用户召回模型
Sean Ellis在他写的《增长黑客》里面提及到最多的方法,就是这种实验增长派。我在他的增长派里面加了一些自己的观点和看法,总结出一个新的实验增长派的模型。
在这个模型中,我们可以看到一共有六步,前五步是固定的,发现问题、提出想法、预期效果、测试矩阵,还有复盘分析。而第六步则是12345、12345……将这个增长模型不断滚起来。
以流失用户召回举例,先看上图:
图中红线代表新增和流失比。因为新增必须大于流失,所以红线正常情况下应该大于100%,才能做到DAU的堆积。
图中蓝色代表的是流失净增加。对“流失”,不同公司的定义也不一样,可能是连续15天没登录APP,也可能是30天,又或者是没有投资,都是根据公司实际情况去定义的。
- 发现问题
可以看到,从2018年11月开始,红线急剧下降至100%以下,且蓝色的柱子净流失的绝对值在增加,说明这段时期处在渠道的投放阶段,流失用户大于新增,这个时候我们就应去做流失用户召回,这是第一个问题。
第二个问题,我们有没有必要做流失用户召回?“应该”和“有必要”其实是两个问题。
金融公司的获客成本大概在500左右,P2P甚至上千,这些平台在用户的拉新、促活、复购等预流失阶段已经花费大量的金钱,到了流失阶段,有些平台就可能选择放弃这些用户,不做再做流失用户召回,这是“有没有必要”的情况。
以50-30的获客成本,有没有必要去做其实没有那么苛刻,是可以去做,而且有必要去做的。这就解决了前两个问题。
第三个问题,流失用户的价格如何去定?在启动这个项目前要有预估,这个价格怎么定?
假如平台的新增获客成本是15元,那它召回用户下限就是3元。
为什么是3元呢?因为有一个魔法数字,叫维护一个老用户的成本是新用户的1/5,所以它的下限是3元,上限是15元。
大家可以这么理解,如果一个用户流失的时间过长,其实他就变成了一个新用户,已经对这个平台陌生了,所以它的价格定在3到15元之间是最为合理的。
最后一个问题是能保证成功吗?这个问题是老板问得最多的。
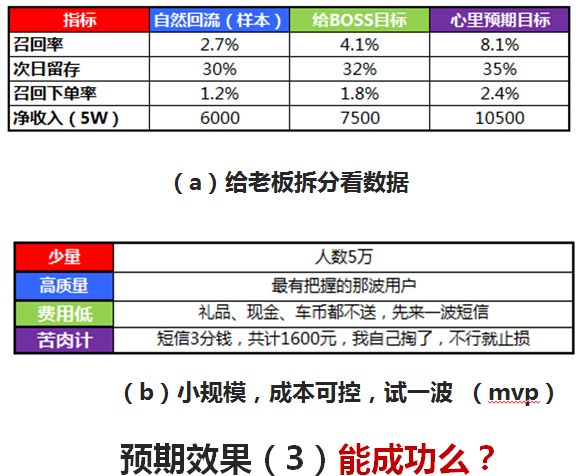
- 预期效果
我们先来回答老板那个问题,能保证成功吗?
先给老板详细拆分数据。
假设用户在流失30天后突然回来,这个的概率是多少,召回率、次留,召回以后的下单率、收入等都能有一个预期的效果。
对于短信的召回、活动的召回等,我们自己也需要有一个心理预期。从图中可以看到,紫色一列召回率的心理预期目标是8.1%,但我跟老板说的时候,肯定是说绿色那一列的召回率4.1%。
这就是我自己的一个小模型,叫8、9、10模型。即说8、做9、吹10。这种模型下,不说100%,也有95%的概率能保证8.1%的召回率。
召回以后,可以跟老板说“你看我这做得多好,比给你的目标超了一倍”,老板就会说“那继续做吧,挺好”。这个就是拆分给老板看的第一个数据。
第二个叫小规模成本可控测试一波,也称之为MVP(最小可行性实验),这是《增长黑客》里经常提到的方法。先挑少量的人 ,比如5万,挑的人是最有把握能召回、流失前质量非常好的一波用户。
不要一上来就给礼品、现金、车币等,先来一波短信看看效果怎样。可以来个苦肉计,告诉老板一条短信3分钱,一共需要XX元,实在不行我就自己掏了吧,先试一下。
先拆数据,然后再小成本可控地测试一波,用这两个数据跟老板说,老板应该都会同意去做的。这个就是预期效果。
(2)提出想法和(4)测试是一一对应的。这是什么意思?
先来看测试矩阵(4)。在测试前先把所有用户进行矩阵分类,比如:
A列是用户质量;
B列是选择触达的工具;
C列是文案;
D列是礼品等。
在做这个矩阵之前,还要给矩阵进行评分,这就来到了ICE模型(2)。
ICE模型是什么呢?就是影响、信心和简易性这三个指标,也是《增长黑客》里最经典的ICE。
通过底下这个矩阵随机组合成上面的矩阵,进行排分以及降序排列,我们再去挑选。假如最大可以承担10组实验组,那就选前10,通过这样的挑选去进行实验。
假如方案1(A1+B1+C1+D1)是最高的,选择push手段触达、文案一、红包,首页(即落地页是短信的首页)这样去测试,然后依此类推。这就是我们实验的准备期和做实验的步骤。
最后一步也是最关键的一步,叫实验复盘。实验复盘能给我们带来很多意想不到的东西,这也是实验增长派最重要的步骤。
在实验复盘的基础上,可以知道这一波什么做得好,什么做得坏。比如说第一周测的是文案,文案召回率最高的是什么样的文案?是设问句。“想知道爱车的真实价格是多少吗?易车全知道”,这种设问是召回效果最好的。
下一周我们在测落地页的时候,就沿用上一周最好的文案去测落地页。每一次的实验积累一小步的成功,堆积起来,最后便转化为大的胜利,这个是实验复盘最核心的东西。
大家在上图中可以看到,我习惯的实验复盘做法是利用一个气泡图加上甘特图的形式。
横坐标是召回率,纵坐标是召回质量。每次做召回质量测试,还会分样本组和实验组,实验组的留存除以样本组的留存,这个数值就叫矢量。气泡图的圈代表ROI,即投资回报率,下面的图表是时间的ICE、发生量、以及召回率的总览。
这就是我的实验增长派模型。
六、技术派-逻辑回归
最后一个给大家分享技术派的逻辑回归模型
1. 魔法数字
大家不要听到“技术”两个字就认为很难,实际上技术派大家经常在用。
什么是技术派?技术派最经典的就是魔法数字,相信大家都不陌生。
那什么是魔法数字?就是基于大数据分析,对业务进行经验性总结的量化结果。
比如金融界的二八定律,互金行业的一九定律,Push的魔法时间是早十晚六,上文提到的维护老用户的成本是新用户的1/5,还有一些国外的例子,比如Facebook发现10天增加7个好友的留存要比没能做到的高得多,twitter10天关注30个大V等等,这都是魔法数字。
但是这都是别人的魔法数字,自己的平台怎么用魔法数字呢?
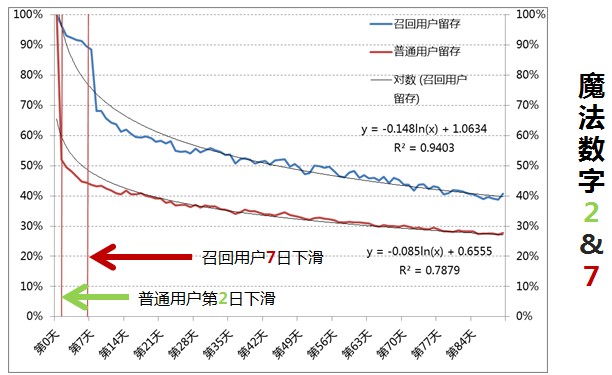
上图中的魔法数字2和7说明了什么情况?是召回用户7天之后才开始断崖式下滑,而新增用户是在第2天就开始断崖式的下降,所以说2和7就是两个魔法数字。
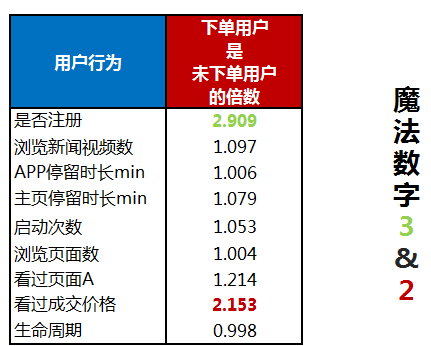
再看上面的表格,魔法数字2和3。第一行是否注册是2.9,接近于3,这表示注册的用户是没有注册用户下单概率的3倍。底下的红字以此类推,也是看过成交页价格的是没有看过成交页价格概率的2倍,所以这个就是魔法数字3和2。
介绍完魔法数字,就带来今天真正的技术派增长的硬核的东西,叫逻辑回归模型。
2. 什么是逻辑回归模型?
逻辑回归模型是什么原理?上图中那根横着的红线就是逻辑回归模型,它将上下两种用户分开,上面是下单用户,下面是未下单用户。我们通过历史用户的下单和未下单的情况进行建模,套用到新用户上,就可以判断新用户下单的可能性。
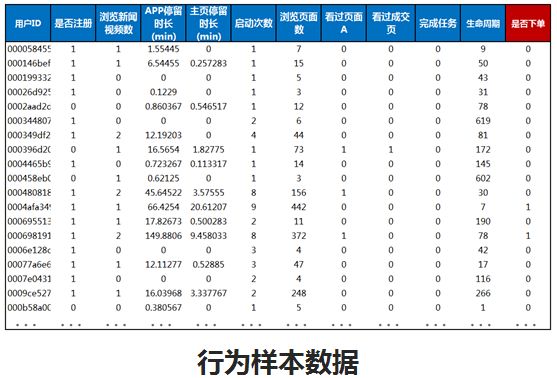
再看用户的行为模型,红色“是否下单”那一列,0代表未下单,1代表下单,这是追踪用户的所有路径,比如说用户在下单和未下单前他都干了什么,以这个为样本数据去模拟模型。
逻辑回归模型在医学和经济预测领域使用更多,并且使用多年了,优势是精度高、时效性强、难度低等。
这也是我跟一个互金类大咖聊天时受到的启发,我问“为什么别人借款借到10万,而我去借款却只借2万,你是根据什么模型做出的判断?”
他告诉我这个就是用逻辑回归模型做的。我因此受到启发:在经济、医学这么严谨的学科里,它都能运营这么多年,这个模型放到易车的业务中应当也是没有问题的。
这个模型在实际业务中的贡献价值是输出具体模型,通过把这根红线给标出来,来判断用户是否下单购买,以及还有哪些行为会对下单有影响。
3. 逻辑回归模型的作用
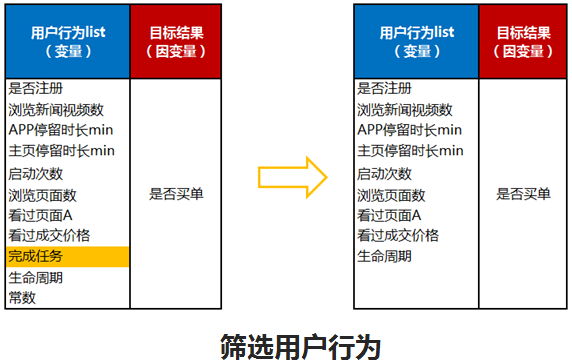
先看筛选用户行为。筛选用户行为这块有一个“完成任务”黄框,但在建模过程中,这个框就没了。这说明什么?说明用户完成的每日签到任务,对下单是没有任何影响的,显著程度非常低。这些用户可能是羊毛党,他是想拿那些积分去换东西,而不是真正想去买车的用户。
第一个显著性给业务的警示就是我们没有必要把过多的资金投入到每日签到这个环节,而是要把钱花在怎么转化用户下单上,这就是资源分配的问题,这是一个筛选用户行为。
第二个是魔法数字的行为影响关系,这可以给我们输出信息:注册用户是未注册用户下单概率的3倍,看过成交价格是没有看过成交价格下单概率的2倍等等这些指标。
第三个是逻辑回归模型的方程式,最后输出的是0和1,判断用户是否下单。这就是它的三个作用,判断显著性、影响倍率,还有它的实际模型。
4. 逻辑回归模型的应用
最后说下逻辑回归的应用,我认为也是最重要的一块。
我常说:“不能把模型落地的数据需求就是在耍流氓”。
你说那个模型好用吗?好用。那你用吗?不用,不会。你没用,就没必要花那么多精力去输出,所以应用真的很重要。
应用分成懒人模式和挑战模式两种。
什么是懒人模式?一些运营人可能看到数据分析就觉得棘手,没有足够的建模经验,这样他只需要去负责用户,了解哪些用户的行为是值得追踪的,把这些行为收集给到技术或者数据分析,让数据分析去把模型完成,最后再转化到模型应用。
而挑战模式其实就是我们做的,通过自己清洗数据-收集数据-建模-调试模型,再到最后的模型应用。
模型应用分为三个阶段:运营手段、产品手段,还有技术手段。
运营手段是什么意思?我把它分为全自动触达和半自动触达。
全自动触达就是前文所说的那个红线,它能判断出0和1,0是不购买,1是可能购买,自动给你发短信或礼品。
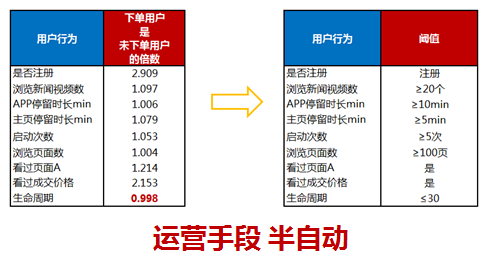
半自动就是我们将这些魔法数字转化为阈值。比如是否注册,浏览新闻的视频数约为20个,APP停留时间大于10分钟等等都是阈值,对满足这些条件的用户使用红包、短信等进行触达。

再来看产品手段。刚才反复强调魔法数字,注册是未注册的3倍,所以我们要改变的是注册率,通过提高注册率来达到提高下单率的目的,这是一种曲线救国的方式,也是我们不断优化探索的方向。
在我们的新版本里,注册页面分成了三步,我们称之为“分布式”。它比老版本的表单式提高了7%的转化。通过提高7个百分点的转化进而提高下单率的转化,这就是产品手段。
最后一个就是技术手段,它比运营手段的效率要高5到6倍,也很好用。
为什么呢?因为技术手段会在满足行为条件的时候,瞬间弹出弹窗发送红包。
假如我注册过,我在你的APP停留的时间也满足了,我也看过成交页的价格,等我再看车型页的时候,很可能是我购买欲望的最高点,这时立马弹出红包,转化率是最高的。
这比运营手段高效,因为运营手段触达的时候可能已经是T+1了,热情也凉得差不多了。所以说技术手段非常好用,推荐大家多用这种即时弹窗,满足条件立刻弹窗。
作者:姜頔