网页搜索策略思考方法
一、产品目标
产品目标:高效地获取信息
1)需求复杂又多变
2)从浩瀚的候选集合里找到正确的信息
不同用户输入同一query表达的需求可能不一致;
同一用户在不同场景输入同一query表达的需求也可能不一致。
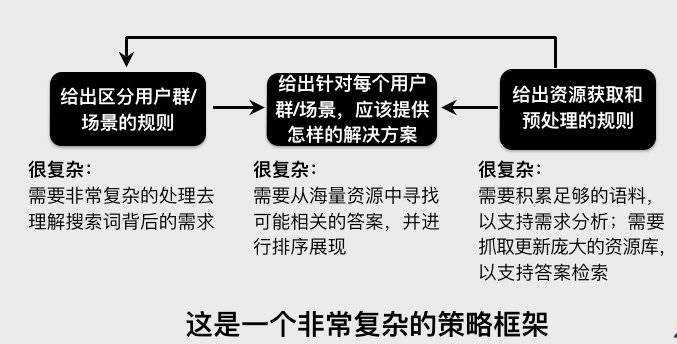
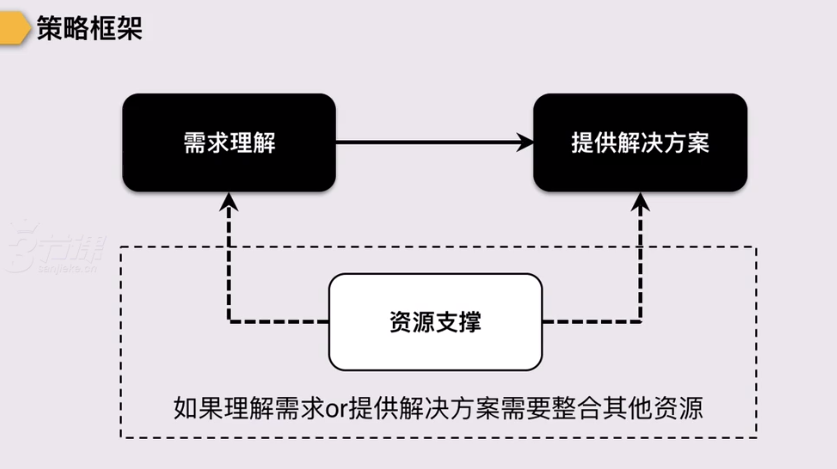
二、需求理解
这里的需求理解其实就是广义的query解析
分为三类:
1)需求明确
A)结构简单清晰的query:经过切词处理即可进行后续检索
例如:黄山火车站订票电话——> 黄山 火车 站 订 票 电话
B)口语化的query:需要进行纠错、同义转换等语义处理
例如:杭州至盐城高速怎么走
——>杭州|至|盐城|高速|怎么|走
——>【map】 【from:杭州】 【to:盐城】 【type:驾车】
C)表达方式很复杂的query:需要进行更加unique的语义处理
例如:
披星()月
吾尝终日而思矣,后面
2)需求明确,对答案有特殊要求
除了统一的query变换外,需要将特定要求转换成搜索引擎可理解的特征
例如:
猪肉最新价格——>资源时效性
3)需求不明确,需要进行需求扩展和预测
例如:
欢乐颂——>欢乐颂视频、剧情介绍、演员表、评论。。。
猩球崛起3——>上映前需要预告片上映时间、上映中需要介绍评价在线购票、下映后需要介绍评论视频
三类扩展维度:
上下文数据:搜了欢乐颂后,用户是否主动更改query搜索欢乐颂视频
类目数据:对于【欢乐颂】这种电视剧专名,天然就有视频、剧情等需求。PM可以提前梳理针对各类目的需求扩展list。
个性化数据:对于特定类目可以进行地域扩展,家乐福——>北京家乐福;电影专名,有的用户更倾向于看剧情,有的倾向看评论。
一个query经过以上分类处理后,会统一成这样的输出,来进行接下来的检索:
【需求类目/需求词】
【需求强度】
【待检索term/pattern】
【其他限定特征(地域等)】
衡量指标:
1)每个query分析规则的召回率和准确率
2)各需求的召回率和准确率
三、解决方案
分为两部分:排序和展现
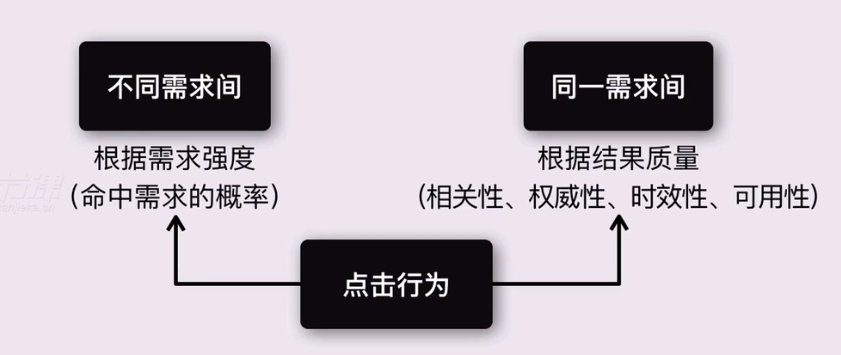
1.排序
不同需求间:根据需求强度(命中需求的概率)
同一需求间:根据结果质量(相关性、权威性、时效性、可用性)
根据用户的点击行为进行调整
实际上,会把需求强度、结果质量、用户点击行为统一成【唯一指标】决定首页结果的排序
LTR:learning to rank 机器学习排序
2.展现
通用策略:将结果页中与query相关的信息提取为标题/摘要,进行飘红等处理帮助用户筛选信息
(对所有搜索引擎,都是将检索对象中用户最关心的内容提取至检索结果列表页,并根据情况以各种强化的样式展现)
细化策略:针对不同需求,又有如下细化策略:
A)对于单一明确信息需求,可以将答案信息之间在摘要中展现
例如:天气、客服电话
B)对于用户接下来路径相对收敛的需求,可以将下一步需求前置,缩短步骤
例如:网易邮箱(登录)、欢乐颂视频(集数)、凡人歌(播放)
C)对于不同资源类型结果,可以针对性优化摘要
例如:视频类、图片类、新闻类、地图类
3.衡量指标
1)每个需求打分、质量打分、展现策略的召回率和准确率
2)用户角度的搜索的满足度
A)基于用户行为的搜索满足度:
摘要满足型需求——>无/很少点击行为
单结果满足型需求——>点击集中于收条结果
主动变换query比例低
翻页比例低等等
B)基于人为评估的搜索满足度:
query前3/5/10结果相关性->基于人为需求判断,当前结果是否能满足;与竞品相比,是否有更好结果未收录、排序是否更优等
session满足度->从用户一个行为片段分析其是否得到满足
四、资源支撑
1.自然语言相关
各类基础词库:用于query切词处理、同义转换、纠错等
语义理解和处理规则:用于query解析
2.网页相关
网页收录(spider):
1)保证各类网页收录覆盖度
2)保证各类网页收录时效性:根据网页类型定义更新频率,重要或时效性要求高的资源可选择站长主动提交的方式
页面分析:
对页面类型进行识别,页面中内容解析、为term附权等等
衡量指标
1)对于NLP相关:各类词库、处理策略的准确率、召回率等;
2)对于网页收录:收录覆盖率、更新时效性等;
3)对于页面分析:各类准确率、召回率等。
五、总结