

01
背景
在互联网行业搜索无处不在,比如:在百度网站搜索技术文档、在百度地图搜索某地点位置、在美团找外卖、在拼多多找商品等都离不开搜索。搜索不同于推荐,需要用户输入query,搜索引擎会返回与query相关性最高的几组点(这里的点可以代表文档、POI、美食、商品等用户要搜的事物),这里称为精确找点,也就是说用户在使用搜索前,已经有明确的查找目标,而搜索缩短了用户与点之间的距离,其重要性不言而喻。本文重点介绍互联网行业搜索的流程、发展和现状,希望对从事和将要从事搜索行业的人员带来一些启发。
02
搜索流程
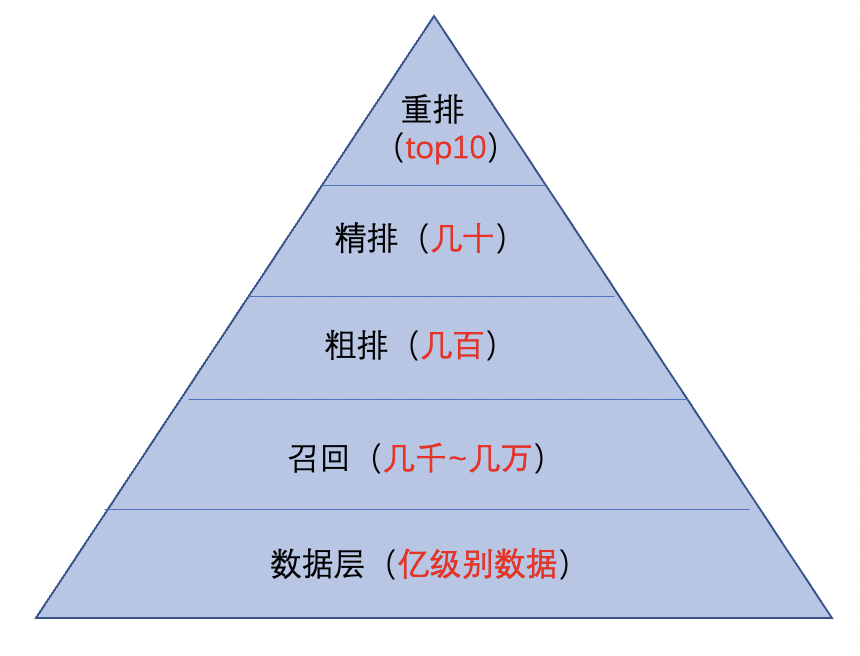
搜索系统一般可以抽象为以下几个维度:离线数据建设、Query理解、召回、排序和展示,在企业中往往也是按照这几个维度划分团队对应开发维护,其中每个维度都可以单独写一篇文档详细介绍,这里我们暂且介绍整个搜索流程。

数据层:搜索的本质是query与数据的匹配,数据的质量直接决定搜索的质量,所以数据是搜索的根本。数据团队负责接入多方数据,最后把非结构化的数据处理成易理解的结构化数据存储(比较复杂繁琐,比如结构化为标题、内容、类型等字段),方便其他团队使用。
Query理解:当用户输入 query时,首先query理解模块对query进行分析与解析,比如输入query [清华大学在哪里],query 理解模块会对该query进行分词(清华|大学|在哪里)、term 重要性标注(清华[2]|大学[3]|在哪里[1])、口语化解析(清华大学[normal]|在哪里[oral])等,并将这些信息传给召回和排序层。
召回:召回的定位是粗筛,粗略的筛选出与query匹配的候选集(量级一般为几千到几万),缓解rank的压力。召回层拿到query理解的信息之后,会根据term重要性等信息构建多路召回服务,在企业比较常见的两种召回服务为倒排索引召回和语义召回。倒排索引是对每个词构建 kv 形式的数据结构;而语义召回是根据用户输入的query 与 doc 构建双塔深度语义模型(常见的模型为 DSSM 等),对 query 和 doc 分别产生语义向量,利用向量进行相似度匹配召回。
Rank:当召回筛选出候选集后,会流转到排序层排序,排序一般分为粗排、精排、重排。
- 粗排,是对召回的数据进行粗略排序,主要作用是快速挑选出符合要求的候选集,量级一般为几百,特点是要求速度快,所以这里常用的模型是树模型。
- 精排,是对粗排的数据进一步的排序,如精排名字所述,特点是需求精确的排序,往往在特征层面上会更加丰富,模型也会更加复杂(如 dfm、dcn、mmoe 等),量级一般为几十,在排序上也最为重要,直接影响用户体验。
- 重排,定位是针对不同的业务需求进行规则调序,比如优先展示某某品牌产品。
- 展示,是直接呈现给用户的,包含数据和样式,比如对某些字体飘蓝、展示由策略生产的推荐理由、展示商品的价格等,更多的由前端同学开发维护。
03
搜索技术应用
在了解搜索的流程之后,本部分聊一下搜索引擎的技术应用,主要是【召回】和【排序】两部分介绍,这两部分也是搜索引擎的核心。
- 召回
最常见的召回方式是倒排索引,所谓倒排索引是离线对数据进行切词,然后按照词粒度构建 kv 格式进行存储,比如有三个短文本:北京邮电大学、清华大学、北京大学,先用分词工具对三个文本进行切词,结果为:北京|邮电|大学、清华|大学、北京|大学,每个词分别作为 key,包含这个key的文本作为 value,这里最终 kv 格式为:北京(key) -> [北京邮电大学、北京大学](value),邮电(key) -> [北京邮电大学](value),大学(key) -> [北京邮电大学、北京大学、北京大学](value),清华(key) -> [清华大学](value),共4组数据。当用户输入[大学]的时候,找到对应的key也就是大学,拉取对应的文本,这里是[北京邮电大学、清华大学、北京大学]三组数据,达到了召回的目的。

构建倒排索引示意图
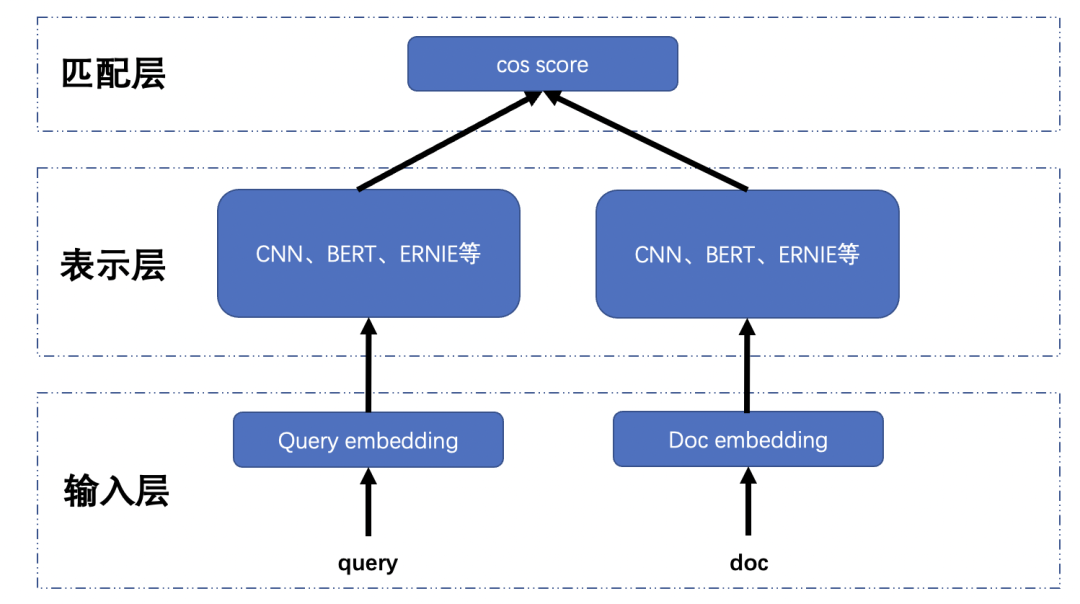
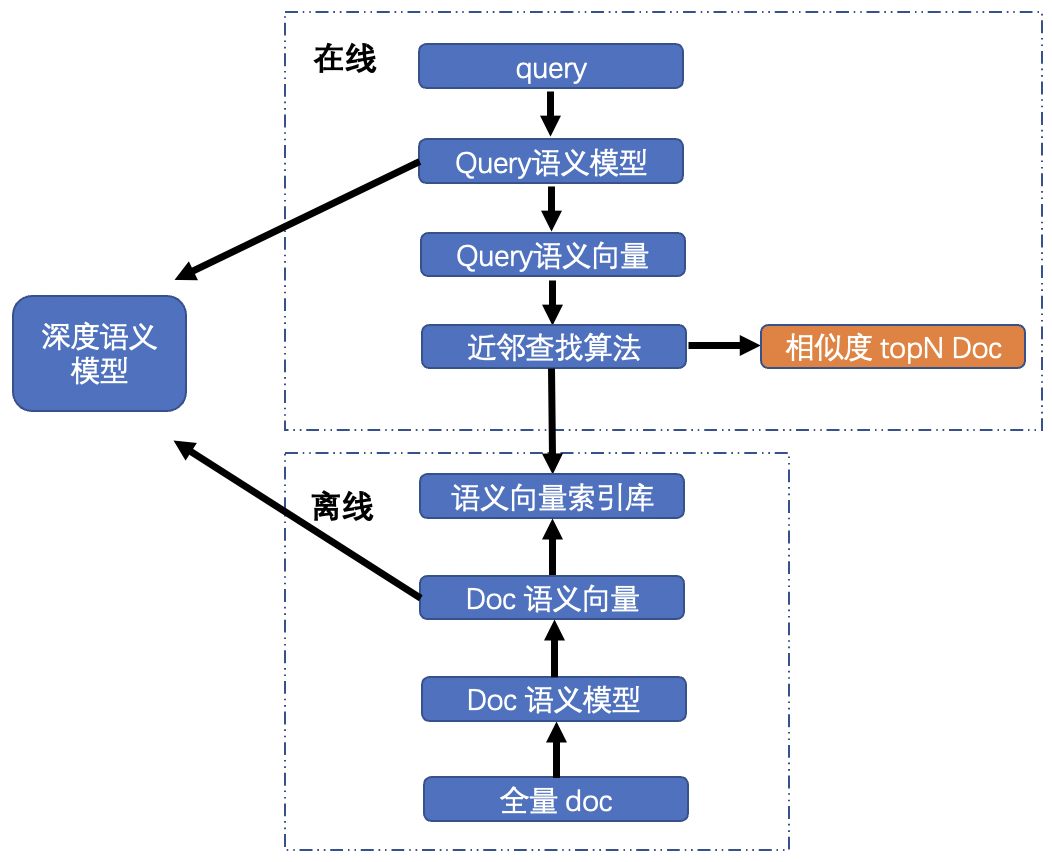
然而,仅仅依靠倒排索引召回会存在召回能力不足的问题,用户输入往往存在多样化的情况,对于同义、错误输入、简称输入等倒排索引召回无法命中其中的key,也就影响召回效果。近年来,随着深度学习的兴起,越来越多的深度学习技术在工业界落地,大大提升了用户体验。其中,以 DSSM (Deep Structured Semantic Models)为代表的深度语义模型为为计算语义相似度提供了一种思路,该架构为双塔结构, query 和 doc各输入到双塔模型产生对应向量,并对doc向量构建离线缓存;当用户输入query,在线产生query向量,用近邻算法(常见fassi、hnsw等)从向量库中检索相似度最高的topN作为语义召回候选集,如下图所示。
当然在召回方式上,还有其他的补充召回,比如个性化召回、统计共现召回,这里不一一详细介绍。
- Rank
从规则排序到线性回归演进
在机器学习不火的时候,最开始甚至使用人工规则,每个特征以人工经验给与一定的权重,优点是模型可控、也具有可解释性,缺点也很明显这样的“人工模型”可泛化能力、自动化能力很差,需要人工根据badcase去调整。后来出现线性回归,能够根据数据自动学习排序的内部规律,优点是解决了人工调整权重的问题,同时也具备强的可解释性,但因为是线性模型,表达和泛化能力、以及缺失数据的处理仍然不足。
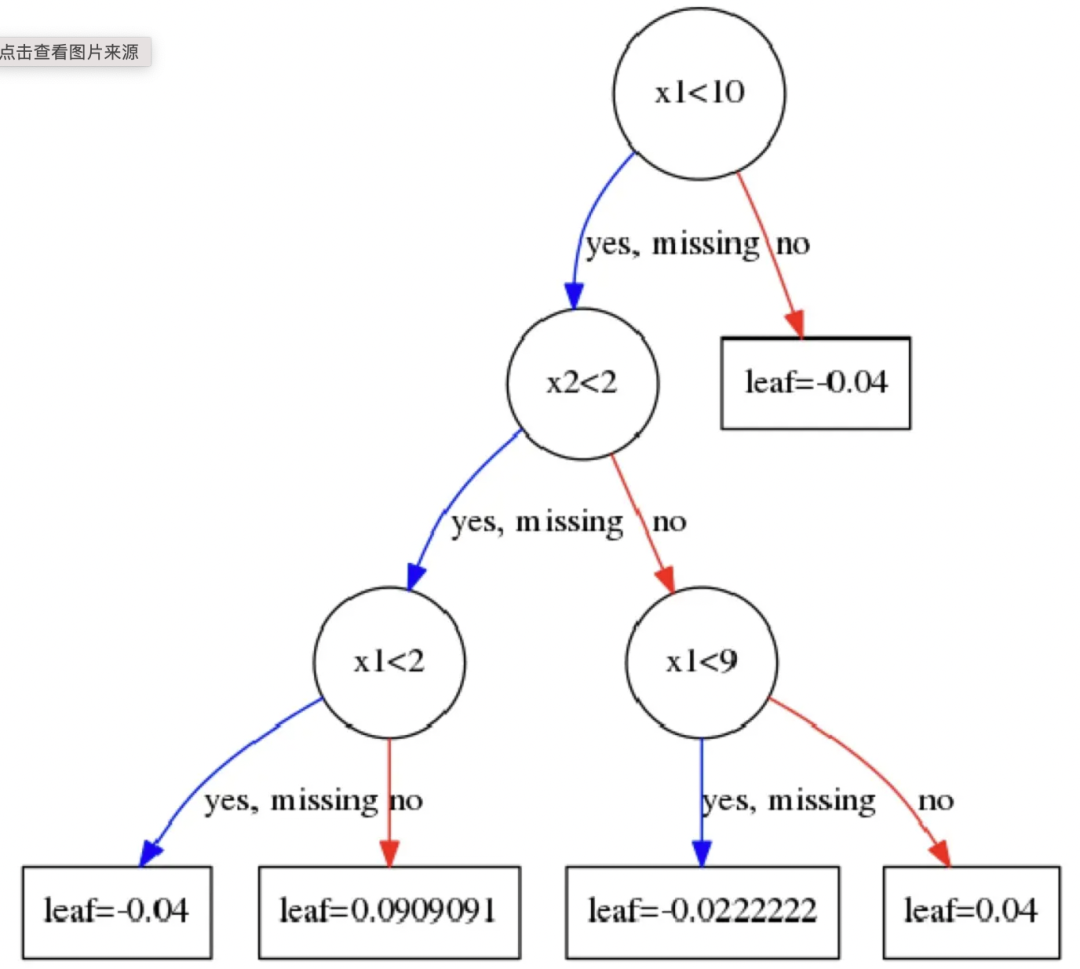
从线性回归到树模型的演进
随着 GBDT、XGB等树模型的发展,越来越多的排序算法应用树模型(至今很多企业仍然使用树模型),主要得益于树模型能够表达非线性空间,泛化能力好,可解释性强,收敛速度快,使其能够在企业中对策略快速迭代,甚至在很多场景要优化NN模型(树模型有很多优点,后续可以展开讲)。
从树模型到NN模型演进
当一个服务流量起来之后,积累的海量数据就会有用武之地,而树模型的容量比较小,当数据达到一定的阈值之后,再增加数据就无法提高相应指标,而DNN因为海量参数具有更大的模型容量,为树模型升级到NN模型提供了可能。
另一个应用DNN模型的逻辑是,树模型往往对连续的数值型输入处理比较好(得益于树模型对特征的排序和信息的分裂),而对本身没有数值大小关系的离散变量表现往往较差,这时NN模型的对离散变量的embedding化往往会起到比较的效果,例如dfm、dcn的embedding交叉,后续可以对排序展开讲讲。

04
总结与展望
本文介绍了搜索的发展历程以及搜索的整个流程,搜索流程共分为5个维度,每个维度都可以单独开展一篇甚至几篇进行详细介绍。虽然搜索系统整个架构在行业中比较稳定,但近期有一些观点对整个行业带来一些启发,比如利用海量数据对大模型(常见的Bert、Ernie等)进行预训练,分别应用两个大模型对召回和排序进行端到端的应用。总之,随着新技术和新想法的不断涌现,搜索引擎还有很多可以完善的地方,需要你我共同建设。
作者:数据人创作者联盟
来源:一个数据人的自留地